

コーパス言語学入門
■コーパスとは何か?
Collins COBUILD英英辞典によると, 「コーパス(corpus)」とは,「言語研究に使用するために大量に収集された書き言葉および話し言葉のテキスト("a large collection of written or spoken texts that is used for language research")」と定義されています。しかし,今日「コーパス」という場合,とくに,機械で処理できるような("machine-readable"な)「電子化テキスト資料」を指す場合が大半です。英語では,すでに,5億語超のBank of Englishや,1億語のBritish National Corpusなどが電子データとして整備されています。
■コーパスを使うには?
時には数億語にも及ぶ大量の電子資料を直接読むことは不可能ですので,コーパスを使う(読む)場合には,語の出現状況を分かりやすく示すコンコーダンサ(concordancer)というソフトウェアを使うのが普通です。下記に示すように,コンコーダンサを使えば,特定の語の使われ方が一覧索引(=コンコーダンス)のように概観できます。
■コンコーダンスソフトとは何か?
語の「ふるまい」をKWIC(Key Word in Context:「キーワードを中心に前後に文脈を表示する」)方式で一覧するソフトのことです。また,共起語の数を自動的に計算する機能などがついているものもあります。
■コーパスは何の役に立つのか?
大量のデータをふまえて語の隠れた特徴や言語の傾向性を明らかにするコーパスは,語法研究・社会言語学・辞書編纂・文体論・文学作品研究など,言語テクストを扱う広範な研究領域に役立ちます。とくに言語教育への貢献の余地は大きいと思われます。実際,英国で刊行されるEFL用の辞書は大半がコーパスに基づいていますし,国内でもコーパス分析を踏まえた英和辞典が刊行されるようになってきました。
■コーパス研究の概要は?
拙著,石川慎一郎(2012)『ベーシックコーパス言語学』の章立てに即して言うと,まず,コーパスに関する基礎論として,「 コーパスとはなにか」(コーパスの定義,概要), 「さまざまなコーパス」(各種コーパスの解決経緯と概要,均衡収集・悉皆収集などの構築理念),「 コーパスの作成」(データ収集,サンプリング,均衡収集,アノテーション等),「コーパス検索の技術」(KWIC,コロケーション分析,単語頻度分析,特徴語分析等),「コーパス頻度の処理」(粗頻度,調整頻度,データの標準化,仮説検定,多変量解析,共起指標等)等の研究が含まれます。また,コーパスを用いた各種の応用的な言語研究として,「コーパスと語彙」(語彙頻度,語彙表,ジャンル別語彙等),「コーパスと語法」(語法,コロケーション等),「コーパスと文法」(慣用的に多用される統語パタン,構文パタン等),「コーパスと学習者」(学習者コーパスを用いた各種研究,中間言語対照分析:Contrastive Interlanguage Analysis等)等も含まれます。コーパス研究は学際的研究の性質が強く,言語学・教育学・心理学・工学などの分野と密接な連携を持っています。こうした,学際的言語研究としてのコーパス言語学の在りようについては,McEnery & Hardie(2014) Corpus Linguistics: Method , Theory, and Practice(CUP)が必読書です。本書は,邦訳として,石川慎一郎訳(2014)『概説コーパス言語学』(ひつじ書房)があります。
オンラインコーパス
■英語コーパス
オンラインで手軽に検索できるコーパスとして,以下のようなものがあります。
BYU British National Corpus(BNC)
イギリス英語1億語を均衡的に収集したコーパスで,英語学の基礎資料として定評があります。1980年代~1993年までのデータが収録されています。ブリガムヤング大学のMark Davies博士によってオンライン版として公開されています。話し言葉,小説,雑誌,新聞,一般(non-academic),学術,その他(misc)の7ジャンルのデータが集められており,ジャンルごとに頻度を比較することもできます。
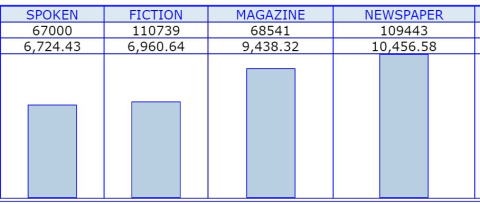
※BNCのspoken他4ジャンルにおける"for"の頻度。話し言葉で少なく,新聞で多いことがわかります。2行目は百万語あたりの換算頻度です。
BYU Corpus of Contemporary English(COCA)
1990年~現在までのアメリカ英語を,話し言葉,小説,雑誌,新聞,学術の5ジャンルで収収集しています。定期的にデータが追加されており,2016年3月現在,サイズはBNCの5倍を超える5.2億語になっています。COCAはオンラインのテキストからデータを収集しており,また,BNCのような緻密なサンプリングは行われていませんが,5億語のデータを検索できるのは魅力です。
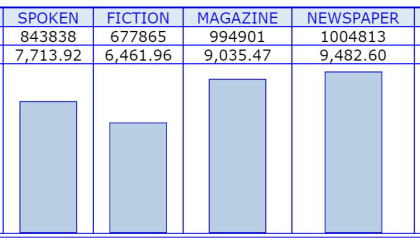
※COCAにおけるforの頻度です。全体的傾向はBNCと同じですが,BNCでは話し言<小説だったのに対し,COCAでは話し言葉>小説となっています。
Japanese EFL Learner Corpus(JEFL)
東京外大投野由紀夫先生監修の日本人中高生1万人の英作文コーパス(70万語)です。このコーパスでは,日本語使用やローマ字使用が認められており,中高生がどのような単語をうまく英語にできなかったか等,ユニークな分析が可能です。

※JPというタグのついているOTOSHIDAMA,dekirunara,itsukahaなどが中高生が英語で書きたくて書けなかった語彙です。
International Corpus Network of Asian Learners of English(ICNALE)
神戸大石川慎一郎研究室で開発したアジア圏10か国の大学生および英語母語話者による書き言葉・話し言葉コーパスです。3,900人,1万サンプル(合計180万語)が収集されており,世界最大のアジア圏学習者コーパスです。トピック等の条件が統制されているので,比較研究の資料として有益です。
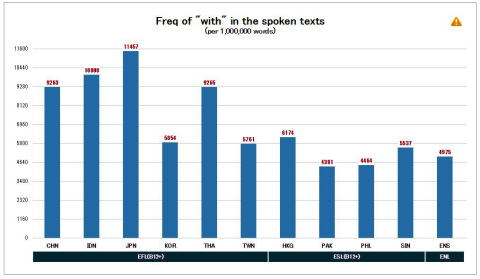
※学習者および母語話者の発話におけるwithの使用頻度を示したものです。総じてEFL学習者はwithを多用し,ESL学習者および母語話者(ENS)はwithをそれほど使用しないことがわかります。EFLの中で日本人学習者(JPN)はwithの使用量が最も多くなっています。
■日本語コーパス
現代日本語書き言葉均衡コーパス(Balanced Corpus of Contemporary Written Japanese:BCCWJ)
国立国語研究所が開発したコーパスで,書籍 (1971〜2005年、22,058件、約6,270万語),雑誌 (2001〜2005年、1,996件、約440万語),新聞 (2001〜2005年、1,473件、約140万語),白書 (1976〜2005年、1,500件、約490万語),教科書 (2005〜2007年、412件、約90万語),広報紙 (2008年、354件、約380万語),Yahoo!知恵袋 (2005年、91,445件、約1,030万語),Yahoo!ブログ (2008年、52,680件、約1,020万語),韻文 (1980〜2005年、252件、約20万語),法律 (1976〜2005年、346件、約110万語),国会会議録 (1976〜2005年、159件、約510万語)併せて,1億語のデータが収録されています。

※「ために」を含むコンコーダンスラインの一部です。Xのために,Xするために,など,表現のパタンが可視化できます。
コンコーダンサの利用
■Antconc
早稲田大学Laurence Anthony先生が開発した,世界標準の多言語対応コンコーダンサです。ダウンロードはこちら。Antconcは下記の検索に対応しています。※現在,解説ページをアップデート中です。過去の解説ページ(2007年版)はこちら。
・コンコーダンス検索(調べたいキーワードを含む行を網羅的に一覧表示します:keyword in context:KWIC表示とも言います)
・コンコーダンスプロット検索(調べたいキーワードがテキストの中のどのあたり[前,真ん中,後半等]に出現するか可視化します)
・ファイルビュー検索(調べたいキーワードを元のテキストに返って確認します)
・クラスター検索(調べたい語を含むn語からなる連鎖を一覧表示します)
・nグラム検索(任意のn語からなる連鎖を一覧表示します)
・共起語(collocates)分析:調べたい語の近傍に出現する語を検索します
・ワードリスト作成:テキストに含まれるすべての語とその頻度を表示します
・特徴語分析:分析対象テキストと参照テキストを比較し,分析対象テキストの側に統計的に有意に多用されている語を一覧表示します。
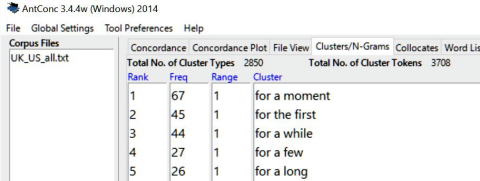
※アメリカ英語・イギリス英語の小説コーパスを検索し,forを含む3語クラスターを検索した結果。頻度1位はfor a momentでした。
アノテーション(annotation)
■アノテーション
コーパスではテキストファイルを大量に収集しますが,高度な分析を行おうとする場合,テキストファイルにあらかじめ必要な情報を追加しておくと便利です。こうした作業を総称してアノテーションと言います。
アノテーションには,品詞情報を付加する品詞アノテーション,意味情報を付加する意味アノテーション,構文情報を付加する構文アノテーションなどがあります。このうち,もっとも基本的で広く使用されているのは品詞アノテーションです。
■品詞アノテーション
個々の語の品詞を判定しようとする場合,その前提になるのは,文字列が正しく語の単位に切り分けられていることです。英語などでは語と語の境界はスペースで物理的に切れているので,語の切り分けの作業を行う必要はなく,個々の語の品詞情報を推定する「品詞タグ付け」の作業だけで済みます。この作業をするソフトウェアを通例「タガー」と呼びます。
一方,日本語や中国語のように,文字列が切れ目なく並んでいる言語では,語の品詞判定を行う前に,文字列を語に切り分ける作業が必要です。この作業を「単語分割」(word segmentation)や「トークン分割」(tokenization)と呼びます。日本語の場合は,たとえば,過去を表す「た」などを独立した「単語」と呼ぶことに抵抗感があるため,「単語」の代わりに「形態素」という用語を用いて,「形態素解析」と呼ぶのが一般的です。通例,単語分割と上述の品詞タグ付けの作業は連続的・一体的に行われ,そうした作業を行うソフトウェアを単語分割器(word segmenter),トークン分割器(tokenizer),形態素解析器(morphological analyzer)などと呼びます。
■オンラインでの品詞アノテーション
最近では,オンラインで,品詞アノテーションの機能を提供するサービスも一般的になってきました。とりあえず品詞アノテーションを体験してみたい場合は,これらを利用するのが良いでしょう。なお,オンラインサービスは,OSに依存しないという大きな利点を持ちます。
(英語)
Free CLAWS
定評あるランカスター大学の品詞タグ付けシステムです。BNCのタグ付けに使用されたことでも知られ,高い精度を持っています。品詞を大まかに分類するC5と,より精緻に分類するC7というタグセットを使用することができます。
(C5) This_DT0 is_VBZ my_DPS pen_SENT ._PUN
(C7) This_DD1 is_VBZ my_APPGE pen_NN1 ._.
CST'S POS Tagger
広く使用されているBrill Taggerをコペンハーゲン大学がオンライン版に移植したサービスです。
This/DT is/VBZ my/PRP$ pen/NN ./.
(日本語)
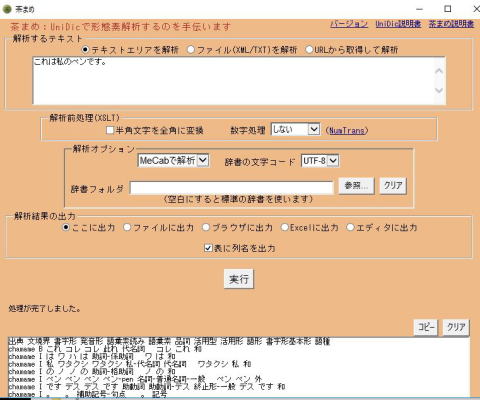
オンライン茶まめ
国立国語研究所が提供するシステムです。BCCWJのタグ付けにも用いられたUNIDICという解析辞書を用いて分析することができます。
これ_代名詞 は_助詞-係助詞 私_代名詞 の_助詞-格助詞 ペン_名詞-普通名詞-一般 です_助動詞 。_補助記号-句点
(中国語)
NLPIR(大数据搜索与挖掘平台:ビッグデータ検索およびマイニングのための処理プラットフォーム)
中国語の単語分割システムとして広く使用されているNLPIRによる品詞解析をオンラインで実行するサイトです。それだけでなく,入力したテキストから得られた単語頻度や共起関係などを統計処理してテキストの特性をグラフィカルに表示することもできます。
这/rzv 是/vshi 我/rr 的/ude1 笔/n 。/wj
■スタンドアロンでの品詞アノテーション
オンラインの品詞アノテーションは便利ですが,大量のテキストファイルを処理する場合など,各自のパソコン上でスタンドアロンで品詞アノテーションを行いたい場合もあるでしょう。そうした場合は,品詞アノテーションのためのソフトウェア(タガー,単語分割器,形態素解析器,トークン分割器)をダウンロードし,インストールして使用することになります。なお,こうしたソフトウェアの多くは工学系の研究者を念頭に開発・配布されており,必ずしも扱いが平易なものばかりではありません。また,通例,辞書ファイルと分析ファイルを別々の場所からダウンロードしてそれぞれインストールし,両者を関連付けする作業が求められるため,インストール段階で躓いてしまう人も多いようです。
以下では,コーパス言語学の入門レベルの方が,英語(Brill,Tree),日本語(IPA,Juman,UNIDIC),中国語(Jieba,NLPIR)の各々について,複数のアノテーションシステムをインストールし,比較して検証できるよう,3つのファイルパッケージを提供しています。これらは,既存のプログラムや辞書データなどを組み合わせて一括ダウンロードできるようにし,平易な解説を添えたものです(Windows用です)。なお,ソフトウェアの著作権はそれぞれの開発者にあります。
(英語)eng_pos_annot
英語の品詞タグ付けを実施するには,タガーをパソコン上で起動し,必要な作業を実行します。タガーには,Brill Tagger(開発者:Eric Brill)やTree Tagger(開発者:Helmut Schmid)などがあります。また,これらをwindows上で使用するためのGUI(graphical user interface)として,Go Tagger(開発者:後藤一章)やTreeTagger for Windows(開発者:北京外国語大学)などの補助プログラムが開発されています。本ファイルパッケージ(eng_pos_annot)は,以下の2種の英語品詞タグ付け環境をPC(windows)上に構築するために必要なプログラムを集約し,必要な修正を加えた上で,平易な解説を付したものです。著作権はそれぞれの開発者に帰属します。
1)Brill Tagger on Go Tagger
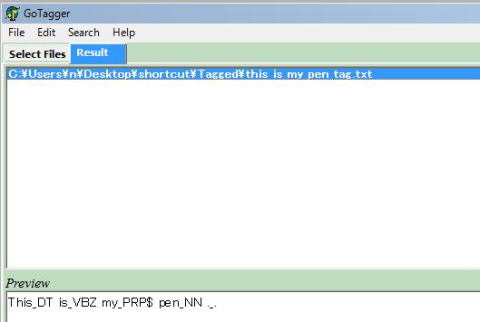
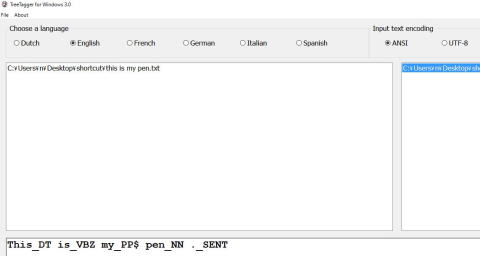
2)Tree Tagger on TreeTagger for Windows 3.0 Lite
(日本語)jpn_pos_annot
日本語形態素解析を実施するには,品詞辞書と,品詞推定システムの2種を組み合わせて作業を実行します。品詞辞書は品詞体系を定義したもので,IPAやUNIDICなどがあります。品詞推定システムは語の品詞を推定するための統計アルゴリズムを実装したもので,Chasen,Mecab,Jumanなどがあります。本ファイルパッケージ(jpn_pos_annot)は,以下の4種の日本語形態素解析環境をPC(windows)上に構築するために必要なプログラムを集約し,必要な修正を加えた上で,平易な解説を付したものです。著作権はそれぞれの開発者に帰属します。
1)IPA辞書 on Chasen
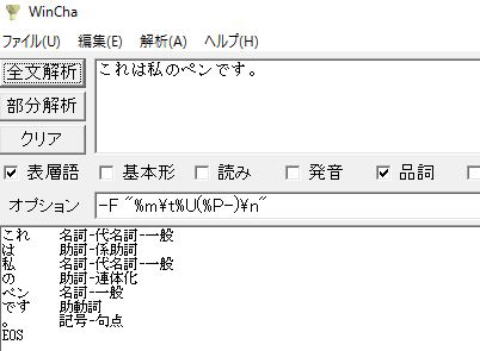
2)Juman辞書 on Juman

3)IPA辞書 on Mecab
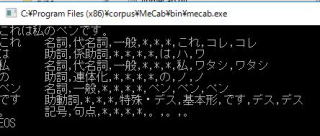
4)UNIDIC辞書 on 茶まめ/Mecab
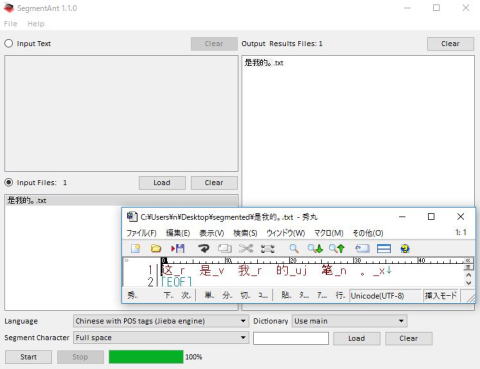
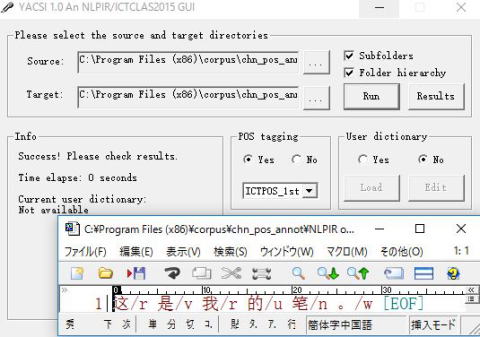
(中国語)chn_pos_annot
中国の単語分割(品詞タグ付け)を実施するには,単語分割システムをパソコン上で起動し,必要な作業を実行します。単語分割システムには,Python用に開発されたjieba(開発者:Baidu,Sun Junyi氏)や,NLPIR/旧称ICTCLAS(開発者:北京理工大 Huaping Zhang)などがあります。また,これらをwindows上で使用するためのGUI(graphical user interface)として,SegmentAnt(開発者:早稲田大学Anthony Laurence)やYACSI(開発者:北京外大 Wu, Liangping, Zhigang Xie & Jiajin Xu)などの補助プログラムが開発されています。本ファイル(chn_pos_annot)は,以下の2種の中国語の単語分割・品詞タグ付け環境をPC(windows)上に構築するために必要なプログラムを集約し,必要な修正を加えた上で,平易な解説を付したものです。著作権はそれぞれの開発者に帰属します。
1)Jieba on SegmentAnt V1.0
2)NLPIR on Yacsi V1.0 (English interface)
■分析検証用サンプルファイル
ウィキペディア英語版,ウィキペディア日本語版,百度百科における「言語学」の項目の一部をUTF8でテキスト化したものです。3言語の分析サンプルとして利用いただけます。
・日本語サンプル
・英語サンプル
・中国語サンプル