最終更新:2016/9/3
特徴クラスター分析とは?
AntconcのKeyword機能を使えば,比較元コーパス(分析対象コーパス,ターゲットコーパス)と,比較先コーパス(対照コーパス,参照コーパス,レファレンスコーパス)を比べ,比較元コーパスを特徴づける語,つまりは比較元コーパスのほうでとくに頻度が多い(または少ない)語を抽出することができます。こうして,たとえば,「Xというテキストでは,atが特徴的に多く,inが特徴的に少ない」などの分析ができるわけです。しかし,これだけでは,atやinのどのような機能が特徴的なのかまったくわかりません。
テキストの特徴をより詳しく分析するためには,個々の単語レベルで議論するよりも,「Xというテキストでは,at that timeが特徴的に多く,in thisが特徴的に少ない」というように,複数語がかたまったクラスター(cluster)単位で特徴表現を調べることが有効です。このとき,at that timeは3語のかたまりなので3語クラスター,in thisは2語のかたまりなので2語クラスターと呼ばれます。なお,こうした語の連鎖については,複数語連結単位(Multiword unit=MWU),語彙束(lexical bundle),nグラム(n-gram),コロケーション(collocation)などと呼ぶこともあります。
特徴クラスターの抽出をAntconcだけ行うのは困難です。そこで,以下では,Mike Scott氏が開発したWordsmith Toolsというソフトウェアを使ってこの作業を行う過程を紹介します。
作業の流れ
今回,分析サンプルに使ったデータは,筆者が収集している中国人英語学習者によるオリジナル作文(CHN_ORIG)80本と,母語話者による修訂済作文(CHN_Edit)80本です。両者を比較してオリジナル作文側の特徴クラスターを検出することで,学習者がうっかり使ってしまいがちな不適切表現を明らかにするのが分析の狙いです。
さて,特徴クラスター抽出では,大別して,以下の3つの作業モジュールが存在します。
(A)比較元コーパスからインデックスリストを作成し,それを基にしてクラスター頻度表を作る
(B)比較先コーパスからインデックスリストを作成し,それを基にしてクラスター頻度表を作る
(C)AとBで作成されたクラスター頻度表を相互に比較し,比較元コーパスにおける特徴クラスターを抽出する
このうち,(B)は(A)と全く同じ作業を別のデータで繰り返すだけです。
以下では,まず,(A)として,中国人学習者のオリジナル作文(CHN_ORIG)を処理する手順を見ていきましょう。
ステップ①準備作業

まず,Wordsmithを起動すると,起動画面内に以下のような選択ボタンが表示されます。

C(コンコーダンス分析),K(キーワード分析),W(語彙リスト分析)の3つの分析がありますが,ここでは,Wを押します。
すると,自動で語彙リスト分析画面が現れます。
画面の左上は以下のようになっています。
ここで,Fileを選びます。
すると,New とOpenがあります。初めてのデータで分析するときはNew,すでに処理済みのデータを呼び出す場合はOpenですが,ここではNewを選びます。
すると,以下のGetting started画面が出ます。
ここで,Choose Texts Nowを押します。すると,分析処理ファイル選択(Choose Texts)画面が表示されます。
左上の白いボックスで読みこむデータを指定します。ボックスの右端にある▽ボタンを押すと,自分のパソコンのエクスプローラ画面が表示されるので,分析したいファイルもしくはフォルダを指定します。
フォルダを指定した場合は自動的に左側の下(Files available)にフォルダ内のテキストが一覧表示されます。
すべてを分析したい場合は,テキスト群の中のいずれかのテキストを選択した状態で,Ctrl+Aを押して,全データを選択状態にします。
その後,中央にある縦長長方形(上下に「>」マークがついている部分)を押すと,選択したデータが右側の選択済みファイルリスト(Files selected)に登録されます。
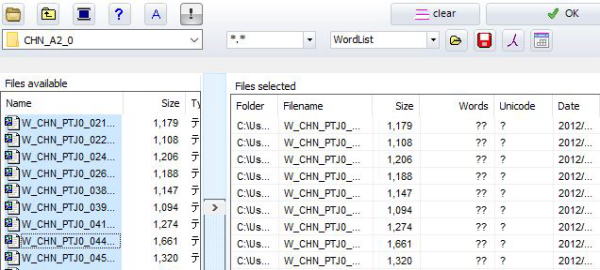
これでステップ1は終了です。
ステップ②インデックスリスト作成・保存

ステップ1の準備を終えた段階で,画面右上のOKボタンを押します。すると,上述のGetting started画面が再度表示されます。
Getting Started画面には,上から順に,Texts Word List Indexの3つが並んでいます。
ここでは,一番下のIndexに注目します。 インデックス処理とは,元のテキストファイルから,個別語の頻度だけでなく,個々の語の位置の情報や連語のつながりの情報も含めて処理を行うことを言います。
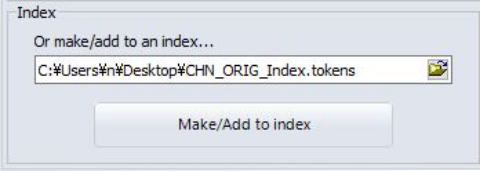
Or make/add to an index...の下にある白いボックスの右端のフォルダのアイコンを押して,自分のパソコンのどの場所に,どんな名前で処理済みのデータを保存したいか指定します。上記の例では,デスクトップ上に,CHN_ORIG_Indexという名前で保存するように指定しました。すると,プログラムが自動でその名前の後に~tokensという語を付与してくれます。
以上を確認してMake/Add to indexを押します。
すると,以下の確認画面が出ます。
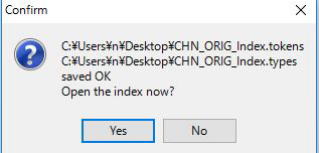
ここはNoを押しておきます。
デスクトップを確認すると,新たに4つのファイルが生成されています。
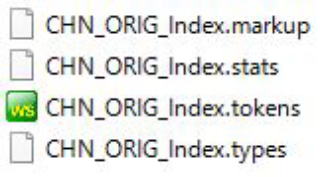
これで,ステップ2の作業は終わりです。
ステップ③ クラスター頻度表作成・保存

ここで,ふたたび,Wordlistの画面に戻り,File < Openと進み,上記で作成したフォルダを指定します。すると,~markup,~tokens,~stats,~typesのうち,tokensだけが自動的に表示されます。
そこで,表示されたファイル(ここではCHN_ORIG_Index.tokens)を選び,「開く」を押します。すると,通常の個別語の頻度ファイルが出現します。
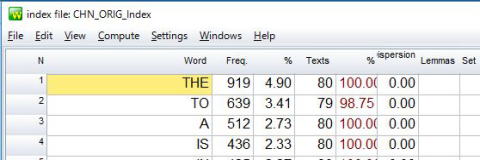
ここで,上部にあるツールバーのComputeを押します。すると以下のポップアップ画面が出現します。
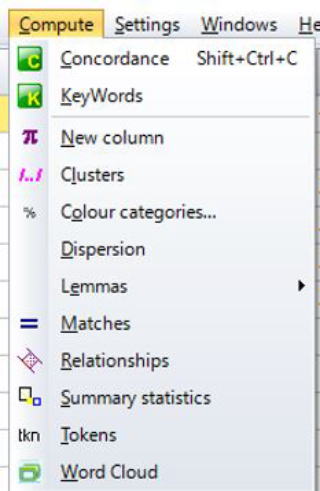
上から4つ目のClusterを選ぶと以下の画面が現れます。
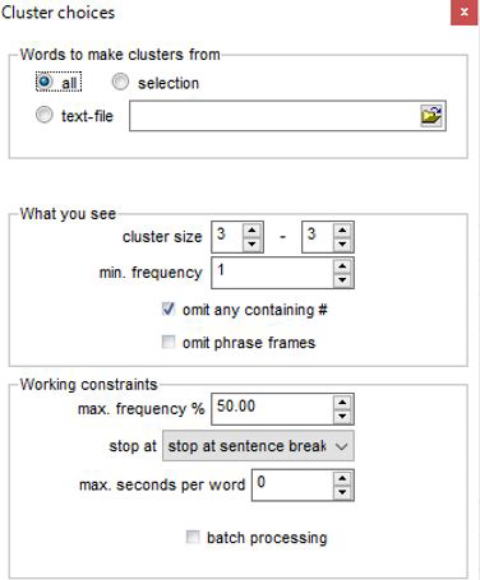
様々な条件設定が可能ですが,ここではできるだけ単純でわかりやすい結果を得るため
Words to make clusters from(機能語や数詞など,クラスター構成単位とみなさない語を設定するかどうか)はデフォルトのall
「抽出基準」(What you see)の中で,
cluster size(何語の連鎖を取り出すか)は2~4(これで2語クラスター,3語クラスター,4語クラスターが同時に出力されます)
min.frequency(どの程度まで低頻度用例を取り出すか)はデフォルトの1
omit any containing #(複数語のワイルドカードを示す#を除くか)はデフォルトどおり☑
omit phrase frames(異なる表記形を同等とみなして計算されるレマレベルのクラスター単位を扱わないようにするか)にも☑を入れる
その他はデフォルトのまま と設定します。
すると以下のようなクラスター頻度表が出力されます。ようやくこれで,比較元データ(CHN_ORIG)のクラスター頻度表が完成したことになります。
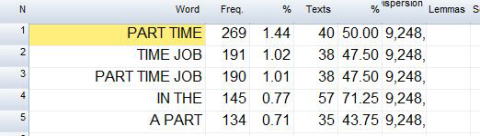
今回は2語クラスター~4語クラスターの区別なく,数の多いものから順に並んでいます。1位と2位は2語クラスター,3位は3語クラスターです。これを確認した段階で,File < Saveと選びます(※Save asではありません!)。

すると,システムがファイル名の後ろに自動でindex_2-4-wordという名前を付加してくれます。これを確認して「保存」を押します。これで,先ほど作成したフォルダの中に新たにlst(リスト)ファイルが作成されました。
ステップ①~③ 比較先データの処理

今度は,比較先データ(ここでは,中国人作文の校閲版データ:CHN_Edit)について,①~③の同じ手順を適用します。
まず,新しい分析データを読みこませるため,最初の画面に戻り,Wordlist < File < New < Choose Texts Nowと選びます。
すると,前回指定済みのファイルが引き続き表示されます。ここで,右上のclearのボタンを押し,指定済みのファイルを消します。これで,空の状態に戻りますので,新たに,比較先データを登録し,①~③の作業を同様に行います。
作業がうまくいけば,デスクトップには,比較元データと比較先データの各々について,5つずつのファイルができているはずです。以後の作業のため,新しいフォルダを作り,そこに移動しておくとよいでしょう。
以上で,比較元・比較先それぞれについて,①~③の作業が終了しました。
ステップ④ 特徴クラスターの抽出

いよいよ最後のステップです。ふたたび,メインの画面に戻り,新たにKのボタンを押します。
File < Newと進みます。
すると,Keyword分析用のGetting started画面が現れます。
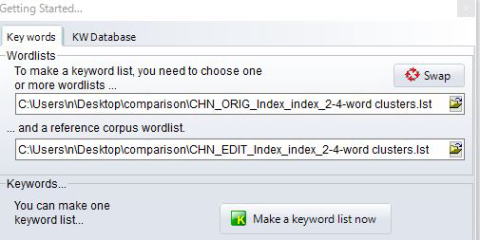
ここでは,2行にわたってファイルを指定するようになっているので,上の行に比較元(CHN_ORIG)のlstファイルを,下の行に比較先(CHN_EDIT)のlstファイルを指定します。その後,Make a keyword list nowを押します。
多くの場合,以下のような確認が表示されます。
特徴語・特徴表現抽出では,本来,2つのデータを比較して,比較元の側で著しく頻度の多いもの,少ないものをすべて抽出するわけですが,そもそも,全体の0.1%に満たないような低頻度クラスターは結果に表示しないようになっている,という意味の確認です。多くの分析では,この措置で問題はないのでOKを押して先に進みます。
すると結果が表示されます。

左から順に,Key word(比較元の側で特徴的な表現),Freq/%(比較元データでの頻度と全体構成比),Texts(比較元のテキスト群のうち,当該表現が出現するファイル数がいくつかったか),RC Freq/%(比較先=参照コーパス=reference corpus側データでの頻度と全体構成比),Log_L(2つのデータにおける頻度の差の大きさを示す対数尤度比統計量:log likelihood ratio=特徴度:keyness),Log_R(log ratio 不詳。現在,詳細確認中ですが,比較先コーパスでの頻度が0だった場合に値が跳ね上がることから,比較先コーパスでの頻度の出かたを示す指標値として使用できそうです),p(2つのデータにおける頻度に差がないという仮説を棄却する上での危険率,通例0.05未満であれば差は有意と決断します)が表示されます。
論文などで使用する場合に備え,File<Save as <Excel spreadsheetと指定し,わかりやすい,デスクトップを保存場所に指定した上で,適当な名前をつけて保存します。以上で処理は終了です。
Save asで保存すると,同じデータをExcelで開くことができます。
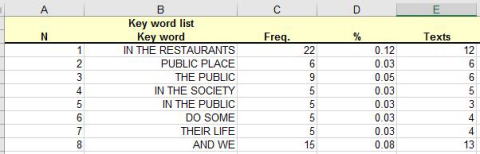
Excelファイルで,Log_Lの値を見ていくと,だんだん下がってきますが,あるところで,最小値となり,その後マイナスになっていることに気づきます。
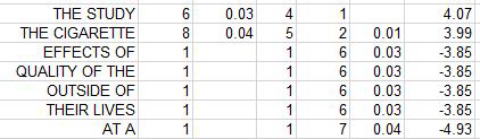
上記の例だと,the cigaretteが+3.89,つまり,比較元コーパスのほうでプラスに特徴的な(つまりは,比較先コーパスより比較元コーパスのほうで頻度が多い)表現の最後です。それ以降,たとえば,effects ofはー3.85となっていますが,これらは比較元コーパスのほうでマイナスに特徴的な(つまりは,比較先コーパスより比較元コーパスのほうで頻度が少ない)表現になっています。これらを総合的に見ることで,比較元を特徴づけるクラスター(つまり,学習者が使っていたのに,校閲でカットされてしまった表現),比較先を特徴付けるクラスター(学習者が使っていなかったのに,校閲者が新規に追加した表現)が,客観的基準で抽出できたことになります。


コーパス言語学講義:テキストを特徴づけるクラスターを抽出する
研究ミッション
石川研究室は,記述言語学・応用言語学の理論的背景に基づき,L1やL2の慣習的言語運用パタンおよびその習得・学習プロセスを科学的手法によって解明することを目指しています。
大学院生募集
石川研究室では,2016年度現在,博士後期課程2名,前期課程4名,合計6名が所属しています。コーパスに基づく科学的手法により,日本語・英語・中国語などの言語研究・習得研究を志している皆さんの受験をお待ちしています。