ICNALE: The International Corpus Network of Asian Learners of English
A collection of controlled essays and speeches produced by learners of English in 10 countries and areas in Asia
Project Leader: Dr. Shin'ichiro Ishikawa, Kobe University, Japan (iskwshin@gmail.com)
Last updated 2018/4/15
The ICNALE Online
About
The ICNALE Online is a user-friendly online query system developed for the analysis of the ICNALE data. After registration, users can conduct KWIC search, collocation search, wordlist search, frequency graph search, and keywords search on approximately 2-million-words of speeches and essays by Asian learners of English as well as English native speakers.
Important Notice
The ICNALE Online is developed to offer those who are not necessarily familiar with corpus linguistics an easy access to the ICNALE data. The data may be occasionally updated and/ or the query algorithm may be changed without notices, which means that the search results may NOT be replicated in the future. If you plan to use the ICNALE for your professional research purposes, we recommend you to use the download version.
How to Use the ICNALE Online
1. Registration
When you use the ICNALE Online for the first time, you are required to register. No need to register twice.
2, Query Functions
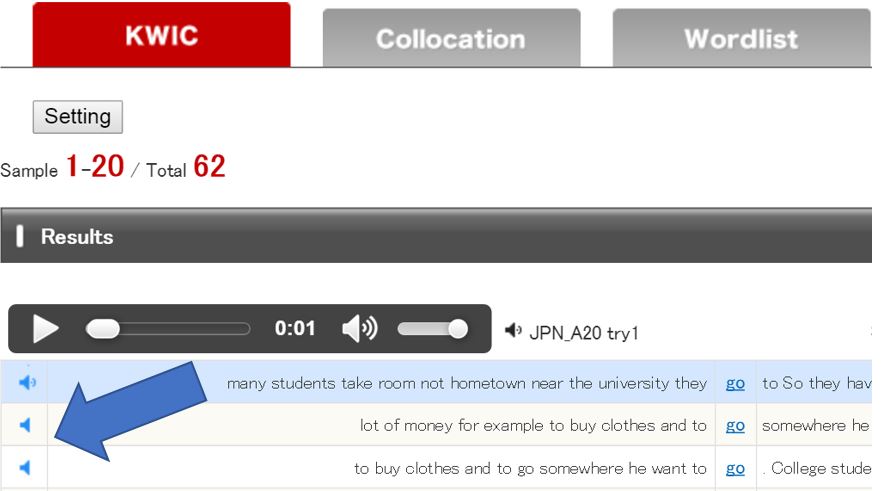
2.1 KWIC Search
KWIC (Keyword in Context) Search shows all the concordance lines in which a particular word or phrase appears. Users can examine how a word or phrase is used in the real context.
Step 1. First, type in a word or a phrase in the Word(S) box.
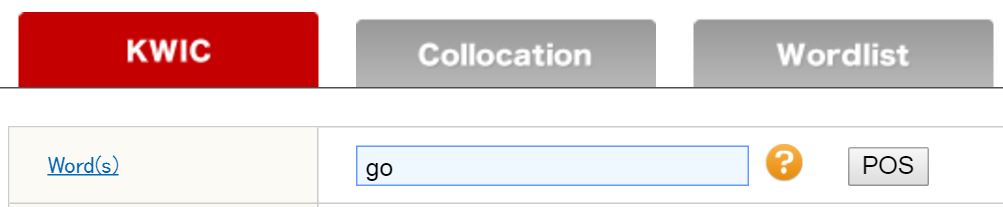
Step 2. You can also use the POS codes.
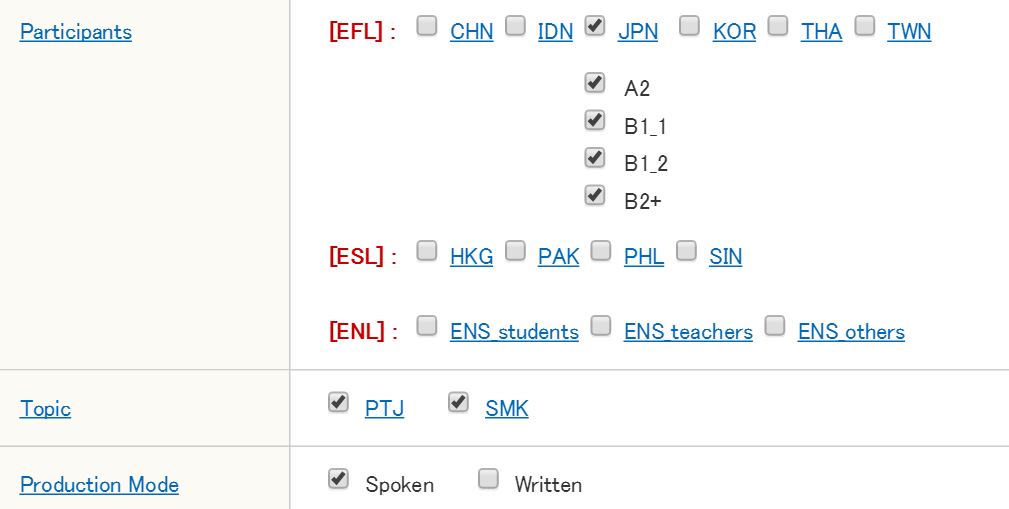
Step 3. Specify participants, topic, and production mode.
Step 4. Concordance lines will be presented. By clicking on the speaker icon, you can hear the speech file online. Please note that the pitch and formant have been changed for anonymization.
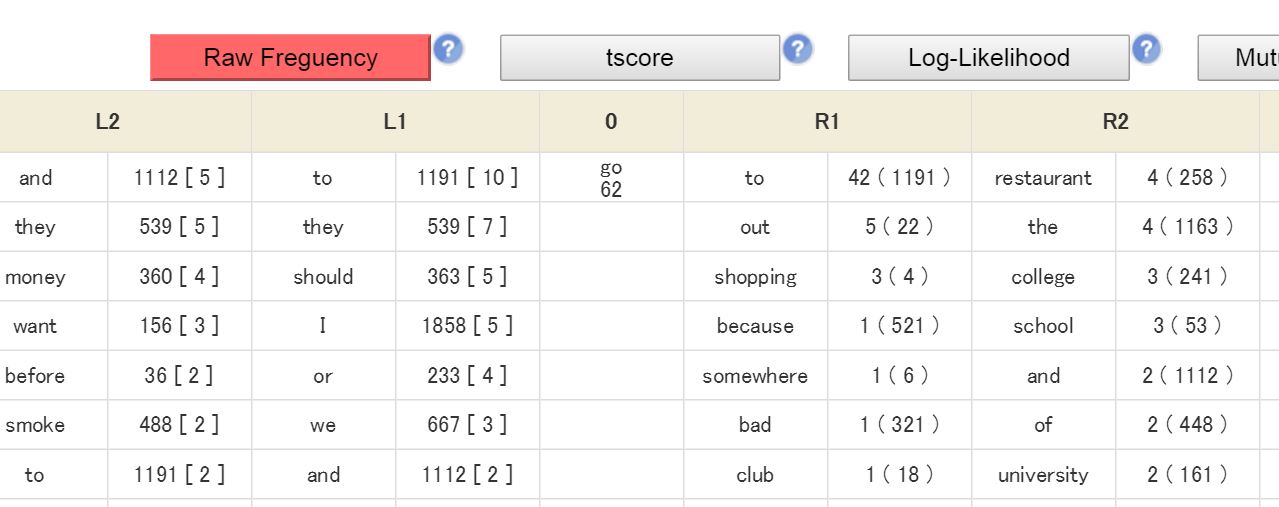
2.2 Collocation Search
Collocation Search shows all the words collocating with the target word within the range of N-3 (3 words before the target) to N+3 (3 words after the target). This kind of output,
which is sometimes called a positional collocation table, helps to examine the lexical environment in which a target word appears.
Users can choose a statistical measure to identify salient collocations from Raw frequency, t score, LL (log likelihood), and MI (mutual information score). In many cases, Raw freq, and LL tend to evaluate high frequent common collocations, while MI tends to evaluate low frequent and peculiar collocations (Ishikawa, 2012).
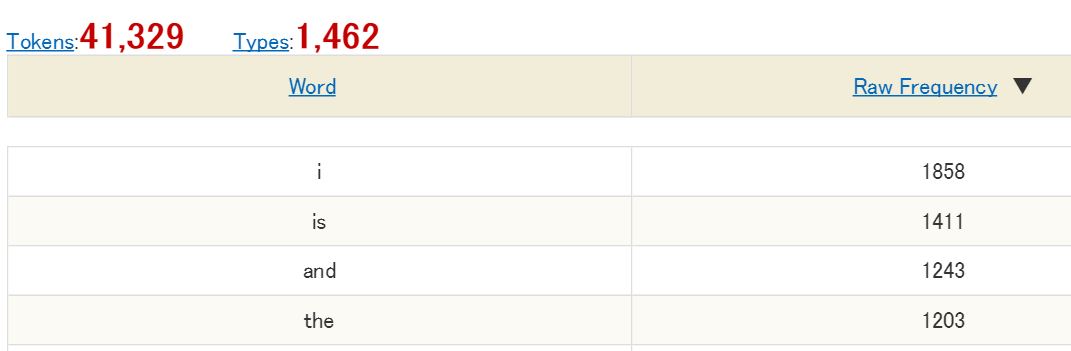
2.3 Wordlist Search
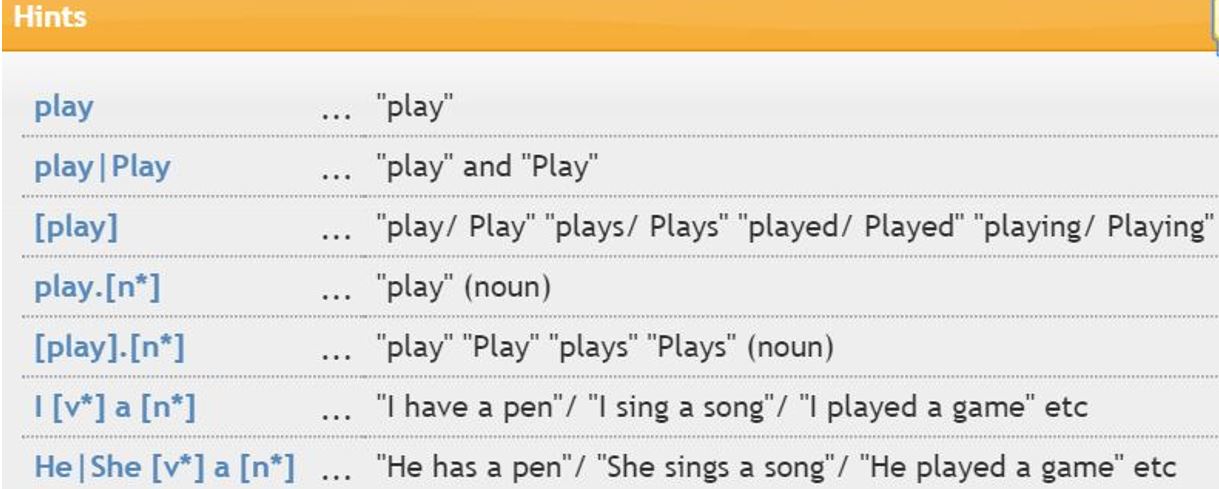
Wordlist search produces a frequency table of all the words appearing in (a part of) the corpus. Users can choose between a case sensitive search ("you" and "You" as different words) and a case insensitive search ("you" and "You" as one word). Also, users can choose between a word form search ("play" and "plays" as different words) and a lemma search ("play," "plays," "played," "playing" as one word). The case-insensitive lemma search setting usually produces a general versatile list.
2.4 Freq graph Search
Freq graph search produces a per-million-word (PMW) freq graph of a chosen word. Users can choose (i) international search or (ii) domestic search. The former shows you how often the word is used by learners in different countries; the latter shows you how often the word is used by learners at different L2 proficiency levels. When choosing the international search, learners' proficiency levels are automatically limited to B1_2 and B2 only.
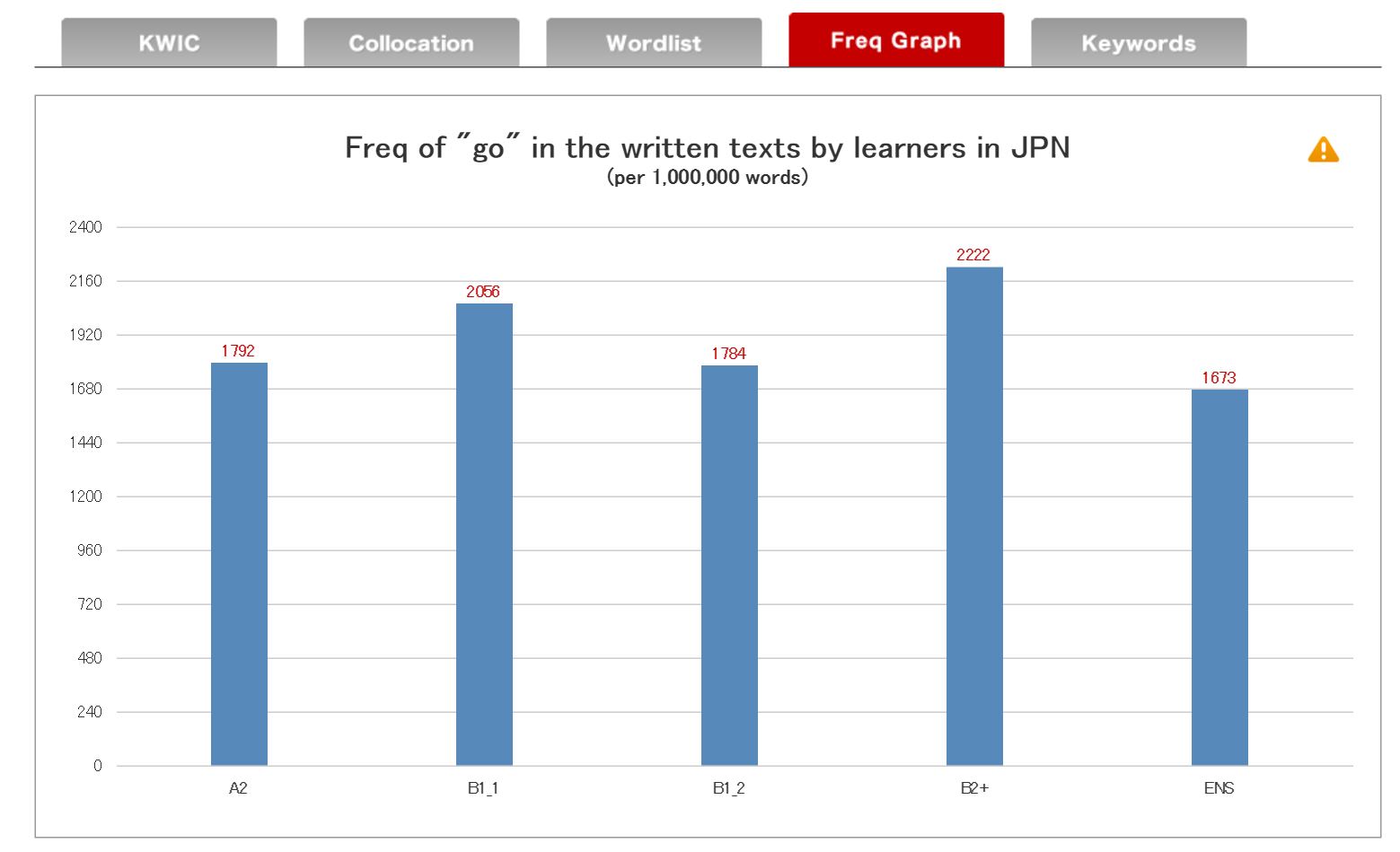
Although the ICNALE is one of the largest learner corpora currently available, distribution of learners' L2 proficiency levels greatly changes according to countries and areas. We advise you to deal with the small data most carefully. Freq zero shown in the graph may be due to the fact that there are no participants in the particular proficiency band. Generally speaking, if the number of participants is smaller than 5 in a particular proficiency band, frequency obtained from the band would be least reliable.

When you check both of Spoken and Written in the production mode, the average frequency value is calculated for a graph.
2.5 Keywords Search
Keywords Search shows all the words statistically overused or underused in one of the two subcorpora to be compared. Users can compare Japanese learners of English with English native speakers, for instance. In this case, the former is called a target, and the latter a reference. By observing keywords characterizing a target, users can easily examine the lexical features of the target group. Users can choose a statistical measure to evaluate the deviance of frequency between X2(chi square) and LL (log-likelihood). Several studies, although not all, suggest that LL is more robust even when the sizes of the two subcorpora are different.