ICNALE: The International Corpus Network of Asian Learners of English
A collection of controlled essays and speeches produced by learners of English in 10 countries and areas in Asia
Project Leader: Dr. Shin'ichiro Ishikawa, Kobe University, Japan (iskwshin@gmail.com)
Last updated 2026/1/20
The ICNALE WEP Version 0.6 has been released!
About ICNALE
1. Brief Outline
The ICNALE (International Corpus Network of Asian Learners of English) is an international learner corpus developed by Dr. Shin Ishikawa, Kobe University, Japan. The ICNALE includes more than 15,000 topic-controlled speeches and essays produced by more than 5,800 college students (incl. grad students) in ten countries/ regions in Asia (China, Hong Kong, Indonesia, Japan, Korea, Pakistan, the Philippines, Singapore/ Malaysia, Taiwan, and Thailand) as well as English native speakers. The ICNALE WEP, a recent addition, includes data from the students in Bangladesh, Brunei, Cambodia, India, Laos, Malaysia, Myanmar, Nepal, and Vietnam. The ICNALE, which currently comprises five data modules: Spoken Monologue, Spoken Dialogue, Written Essays, Written Essays Plus, and Edited Essays, has become one of the largest learner corpora publicly available.
As a part of the ICNALE project, we have also hosted international symposiums, Learner Corpus Studies in Asia and the World (LCSAW), and published the LCSAW conference proceedings (ISSN: 2187-6746).
Table 1. The structure of the ICNALE major modules (As of January, 2026)
| Modules | Latest Version | Updated | Contents | # of participants | # of samples | # of words |
| Spoken Monologues (SM) | V2.1 | 2023/06 | 60-seconds monologues about two ICNALE common topics | 1,100 | 4,400 | 500,000 |
| Spoken Dialogues (SD) | V1.4 | 2023/06 | 30-40-minutes oral interviews including picture descriptions and role plays, and 3-5-minute follow-up L1 reflections. Interview tasks are related to two ICNALE common topics | 425 | 4,250 | 1,600,000 |
| Written Essays (WE) | V2.6 | 2025/01 | 200-300-word essays about two ICNALE common topics | 2,800 | 5,600 | 1,300,000 |
| Edited Essays (EE) | V3.1 | 2023/06 | Fully edited versions of learner essays about two ICNALE common topics. Rubric-based essay evaluation data is also included | 328 | 1,312 | 150,000 |
| Written Essays Plus (WEP) | V0.6 | 2026/1 | 200-300-word essays about two ICNALE common topics collected from new Asian countries | 1,170 | 3,340 | 570,000 |
| Total # | --- | --- | 5,823 | 18,902 | 4,120,000 |
Table 2. The structure of the ICNALE Global Rating Archives
| Module | Latest Version | Updated | Contents | # of participants | # of samples | # of words |
| Global Rating Archives (GRA) | V 2.1 | 2024/03 | + Ratings of 140 speeches and 140 essays by 80 raters with varied L1 and occupational backgrounds. + Plus fully edited versions of 140 essays. |
280 samples X 80 raters |
22,400 | (Edited essays) 65,000 |
Table 3. Related Data set
| Module | Latest Version | Updated | Contents | # of participants | # of samples | # of words |
| Written Essays UAE | V 1.0 | 2018/04 | Comparable essays were collected from college students in United Arab Emirates | 200 | 400 | 47,000 |
2. Key Features
In the ICNALE project, we have paid attention to seven principles: 1) a focus on Asian learners, 2) collection of varied modes of learner English , 3) condition control, 4)proficiency control, 5) learner backgrounds survey, 6) NS' reference data collection, and 7) open distribution.
2.1 Focus on Asian Learners
Considering that European learner data has been already collected in the corpora such as the International Corpus of Learner English (ICLE) and the Louvain International Database of Spoken Interlanguage Database (LINDSEI), the ICNALE has focused on Asian learners. It includes the data of learners both in ESL regions (Hong Kong, Pakistan, the Philippines, and Singapore) and in EFL regions (China, Indonesia, Japan, Korea, Taiwan, and Thailand), which enables users to study not only learner English but also varied Englishes in Asia.
2.2 Collection of Varied Modes of Learner English
The ICNALE has collected both of spoken and written productions by learners. Also, it pays attention to difference between monologue and dialogue in oral production. Users can compare different modes of English produced by learners.
2.3 Condition Control
The ICNALE aims to be a truly reliable database for any type of contrastive interlanguage analysis (CIA.). Therefore, the ICNALE rigidly controls prompts and tasks. The topics are common both for essays and spoken monologues and learner are required to show their opinions about two statements: (a) It is important for college students to have a part-time job. and (b) Smoking should be completely banned at all the restaurants in the country. Dialogue tasks are also related to those topics. In addition, other parameters such as the time for writing an essay, the length of an essay, the time for speeches, and the structure in the interviews, are also controlled. This guarantees the reliability of a contrastive analysis using the ICNALE.
2.4 Proficiency Control
The ICNALE team has required all the learners to take a standard L2 vocabulary size test (VST) covering the top 5K word levels (Nation & Beglar, 2007), and also to present their scores in the high-stake English proficiency tests such as TOEFL and TOEIC. Then, all the learners have been classified into four kinds of CEFR-linked proficiency bands: A2, B1_1 (B1 low), B1_2 (B1 high), and B2+, based on their scores in the proficiency tests or in the VST. The score/ level mapping scheme is shown below:
Table 1. Mapping of the Test Scores on the CEFR Proficiency Bands
| Levels | TOEIC | TOEFL PBT | TOEFL iBT | IELTS | STEP | TEPS | CET | VST |
| A2 (Waystage) | -545 | -486 | -56 | 3+ | 3+ | ---- | --- | -24 |
| B1_1 (Threshold; Lower) | 550+ | 487+ | 57+ | 4+ | 2+ | 417+ | 4+ | 25+ |
| B1_2 (Threshold: Upper) | 670+ | 527+ | 72+ | 5+ | 2+ | 513+ | 4+ | 36+ |
| B2+ (Vantage or higher) | 785+ | 567+ | 87+ | 5.5+ | Pre1+ | 608+ | 6+ | 47+ |
+ How were the test scores related to the CEFR levels?
We determined the mapping scheme above in 2010, based on the official mapping guidelines offered by administrators of TOEFL (N/A now; See the old site), IELTS (N/A now), TOEIC , TEPS (N/A now; See the old site), and STEP. TOEFL PBT (ITP) / TOEFL iBT conversion was based on the ETS 2005 guideline. Some links are now broken, but you can see these mappings in many public documents including the MEXT (Ministry of Education, Science, Sports and Culture of Japan)'s July 2014 report . ETS, however, has recently released a new report on the mapping of the TOEFL iBT scores on the CEFR, which relates 42+ to B1, and 72+ to B2. This new mapping is also shown in the MEXT's March 2015 report . 42+ and 72+ in TOEFL iBT are converted to 440+ and 533+ in TOEFL PBT (ITP). Currently, the ICNALE uses the 2010 mapping scheme shown above.
+ Why did we measure learners' knowledge of the top 5,000 words?
Meara & Milton (2003) [The Swansea Levels Test, X-LEX] and Milton (2010) state that it is appropriate to measure the vocabulary size of non-native speakers with a ceiling of 5,000 words. Therefore, we used fifty test items in the 1000-5000 word levels of the Monolingual Version of VST(14,000 words).
+ How were the VST scores related to the CEFR levels?
There seem to be no reliable conversion guidelines between vocabulary size and CEFR levels. Based on the analysis of Greek and Hungarian EFL learners, Meara & Milton (2003) relate the size of 2500+ words to B1, that of 3250+ words to B2, that of 3750+ words to C1, and that of 4500+ words to C2, but this conversion seems to overestimate the L2 proficiency of Asian learners. Therefore, we conducted a linear regression modeling of 268 Asian participants who have taken both of the TOEIC test and the VST to obtain a conversion formula: TOEIC=10.495 * VST + 289 (R 2=.21). Thus, learners' VST scores were converted into the TOEIC scores first, and then into the CEFR levels.
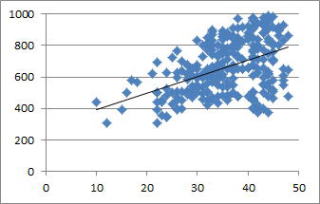
Fig, Scatter plot (TOEIC Scores X VST Scores)
2.5 Learner Background Survey
Using a questionnaire, we collected varied participants' background information, which covers (A) learners' attributes, (B) type of their motivation to learn L2, and (C) their L2 learning backgrounds. Download the learners' info sheet from the download page.
(A) Basic Attributes: Sex, Age, Grade, Years of Studying English, Major, Academic Genres (Humanities, Social Sciences, Science and Technology, Life Science)
(B) Motivation: Participants were required to judge to what extent they agree with 12 statements below with a point from 1 (Strongly disagree) to 6 (Strongly agree).
I study English because ...Q1 I find pleasure when I understand the content sufficiently./ Q2 I want to get a better job in future. / Q3 Learning content is more important than being awarded high grades. / Q4 I want to be socially acknowledged. / Q5 Being awarded high grades is important for me. / Q6 Learning English is what we have to do anyway. / Q7 I want to achieve a good mark in the tests. / Q8 I am interested in the content, even if it is difficult. / Q9 Learning something new is fun, even if it is difficult. / Q10 I find pleasure in discovering something new. / Q11 I want to get a better grade than others. / Q12 Increasing English knowledge is fun.
Q1/3/8/9/10/12 concern the integrative motivation, which includes the interests in L2 or its culture and the want to have interactions with or be integrated into its speech community, while Q2/4/5/6/7/11 concern the instrumental motivation, which includes the want to achieve some practical goal (passing the exam, getting a better grade, getting a better job, getting a job skill, getting a promotion etc.) by using L2 as an instrument. Integrative and instrumental motivations are roughly in accordance with intrinsic and extrinsic motivations. Some studies claim that integrative (intrinsic) motivation often facilitates L2 learning in the long span. In order to grasp participants' overall motivational tendency, we calculated four kinds of motivation scores: INTM (Integrative Motivation Score) (the mean of the responses to Q1/3/8/9/10/12), INSM (Instrumental Motivation Score) (i.e., the mean of Q2/4/5/6/7/11), INTM+INSM (Motivation Strength Score), and INTM-INSM (Integrative Motivation Orientation Score).
(C) L2 Learning Backgrounds: Participants were required to judge to what extent they agree with the 22 statements below with 1 (Strongly disagree) to 6 (Strongly agree) points.
When I was a primary school student...Q13 I often used English in class. / Q14 I often used English outside class.
When I was a secondary school student... Q15 I listened to English a lot in class./ Q16 I read English a lot in class./ Q17 I spoke English a lot in class. / Q18 I wrote English a lot in class./ Q19 I listened to English a lot outside class./ Q20 I read English a lot outside class./ Q21 I spoke English a lot outside class. / Q22 I wrote English a lot outside class.
Now at college... Q23 I listen to English a lot in class./ Q24 I read English a lot in class./ Q25 I speak English a lot in class./ Q26 I write English a lot in class./ Q27 I listen to English a lot outside class./ Q28 I read English a lot outside class./ Q29 I speak English a lot outside class./ Q30 I write English a lot outside class.
So far...Q31 I have been taught by English native speakers./ Q32 I have been taught English pronunciation./ Q33 I have been taught speaking or presentation./ Q34 I have been taught essay writing.
In order to grasp participants' overall L2 learning backgrounds, we calculated three types of scores: (C1) frequency of using/ learning L2 at primary schools (Q13/14, PRIMARY), secondary schools (Q15-22, SECONDARY), colleges (Q23-30, COLLEGE), in schools (Q13/15-18/23-26, INSCHOOL), and out of schools (Q14/19-22/27-30, OUTSCHOOL)
(C2) frequency of using/ learning a listening skill (Q15/19/23/27), a reading skill (Q16/20/24/28), a speaking skill (Q17/21/25/29), and a writing skill (Q18/22/26/30) in L2, and (C3) experiences of being taught by native-speaker teachers (Q31, NS), and learning pronunciations (Q32, PRONUNCIATION), presentations (Q33, PRESENTATION), and essay writings (Q34, WRITING).
2.6 NS' Reference Data Collection
The ICNALE includes the production data by native speakers (NS) of English. They were given the same tasks and required to write or speak in the same conditions, which guarantees the reliability in an NS/ NNS comparison. When collecting NS data, we need to be careful about their geographical and demographic diversity. Thus, we have collected the data of three kinds of NS: (a) college students, (b) English teachers, and (c) adults with varied job backgrounds. Also, we have paid attention to a balance in the nationalities of NS: USA (65% in Speech Monologue Module/ 57% in Written Essays Module), UK (17%/ 14%), Australia (11%/ 8.5%), Canada (7%/ 6.5%), and others (>1%/ 6.5%).
2.7 Open Distribution
The ICNALE is distributed in two ways: an online version and a download version. The former is available through a user-friendly query interface, The ICNALE Online .
3. History
The ICNALE project began in 2007, and we have developed a variety of data modules since then. "ICNALE Written Essays 22" has been renamed as "ICNALE Written Essays Plus (WEP)."

4. Development Team
Project Leader --- Shin'ichiro Ishikawa (Kobe University)
The ICNALE Spoken Monologues Development Team
China---Yuanwen Lu (Shanghai Jiao Tong University), LIU Rui (Jinggangshan University), Xinghua Liu (Shanghai Jiao Tong University), Enyu Feng (Southeast University, Chengxian College, Nanjin)
Hong Kong---WONG Suzanne Shu Shan (Chinese University of Hong Kong)
Indonesia---Leonardi Lucky Kurniawan (Polytechnic of Ubaya, Surabaya), Prihantoro (Universitas Diponegoro), Hanung Triyoko (TAIN Salatiga)
Japan---Shin'ichiro Ishikawa (Kobe University)
Korea---Xinghua Liu, Kyong-Ae Yu (Chung-Ang University), Hye-Sook Kim (Konyang University), Paik Kyungsook, Eunbi Kwon (Hanyang Women's U)
Pakistan---Muhammad Asim Mahmood (Government College University), Moazzam Ali (University of Gujrat)
The Philippines---Mari Karen L. Gabinete (De La Salle University-Manila)
Singapore---Vincent Ooi (National Singapore University)
Taiwan (Chinese Taipei)---Ming Huei (John) Lin (Tamkang University)
Thailand---Penpitcha Prakaiborisuth (King Mongkut's University of Technology)
The ICNALE Written Essays Development Team
China --- Katsuki Mayumi (Dalian University of Technology), Fang Li (Wuhan University), Lu Yuanwen (School of Foreign Languages, Shanghai Jiaotong University)
Hong Kong --- John Milton (Hong Kong University of Science & Technology)
Indonesia --- Leonardi Lucky Kurniawan (Polytechnic of Ubaya, Surabaya)
Japan --- Shin'ichiro Ishikawa (Kobe University) / Yuka Ishikawa (Nagoya Institute of Technology)
Korea --- Sook Kyung Jung (Daejeon University) / Oryang Kwon (Seoul National University)
Pakistan --- Asim Mahmood (Government College University (GCU) Faisalabad)
The Philippines --- Karen L. Gabinete (De La Salle University-Manila)
Singapore --- Vincent Ooi (National Singapore University)
Taiwan (Chinese Taipei) --- Siaw-Fong Chung (National Chengchi University)
Thailand --- Sonthida Keyuravong / Punjaporn Pojanapunya (King Mongkut's University of Technology, Thonburi)
The ICNALE Written Essays Plus Development Team (As of July 2025)
Bangladesh---Faiz Hossain (East West University)
Brunei-- Zayani Zainal Abidin (Universiti Brunei Darussalam)
India-- Sukhwinder Singh Oberoi (Guru Hargobind Sahib Khalsa Girls College Karhali Sahib, Patiala, Punjab), Ankitha Arun (Vemana Institute of Technology), Joan Agdeppa (University of Manitoba), Sirigirajo Meekakshi (IIT), K. Venu Madhavi/Udaya Muthyala/Pusuluri Sreehari (The English and Foreign Languages University, Hyderabad, Lalitha Bai (Vidya Jyothi Institute of Technology, Hyderabad)
Cambodia-- Kimyi Kimyi (Western University), Sean Saroun (universities in Siem Reap)
Laos-- Sisoury Phommaseng (Souphanouvong University),
Malaysia--- Lee Huan Yik (University of Technology Malaysia: UTM), Warid Bin Mihat (Academy of Language Studies of Universiti Teknologi MARA Kelantan Campus), Warid (Institut Pendidikan Guru Malaysia )
Myanmar-- Aye Mya Phyu (University of Yangon)
Nepal--Krishna Prasad Bhattarai (Tribhuvan University)
Vietnam -- Pham Quy (Ton Duc Thang U), Loan Nhị Hà Ha (University of Economics - Ho Chi Minh City), Cao Hong (Vietnam National University), Dinh Thi Mai Anh (Vinh University/ Nottingham Trent University)
Mongolia -- Munkhzaya MANDAKH (Mongolian National University of Medical Sciences)
The ICNALE Spoken Dialogues Development Team
China ---Vicky, Li Linzhen (Xi'an University of Technology), Shin'ichiro Ishikawa (Kobe University)
Hong Kong --- Charles Lam (Hang Seng Management College)
Indonesia --- Prihantro (Universitas Diponegoro)
Japan --- Shin'ichiro Ishikawa (Kobe University)
Korea --- Sue Woo (Konyang University), Tecnam Yoon (Chuncheon National University of Education)
Malaysia --- Rafidah Kamarudin, Muhammad Izzat Rahim (Universiti Teknologi MARA, Negeri Sembilan Campus)
Pakistan --- Moazzam Ali (Government College University (GCU) Faisalabad)
The Philippines --- Jessie S. Barrot (National University, Philippines), Joan Y. Agdeppa (University of Manitoba, Canada), Karizza P. Bravo-Sotelo (Mapúa University), Rafael Paz (Polytechnic University of the Philippines)
Malaysia --- [Now under construction]
Taiwan (Chinese Taipei) --- Ariel Yi-ju Wu (Chinese Culture University), Yen-Liang (Eric) Lin (National Taipei University of Technology)
Thailand --- Rinda Warawudhi (Burapha University Chon Buri), Kemtong Sinwongsuwat (Prince of Songkla University-Hat Yai), Kornsak Tantiwich (Tap) (Prince of Songkla University-Hat Yai)
The ICNALE Global Rating Archives Development Team (Academic members only)
Canada --- Jeannine Brandt/Sana Abdulsalam/Rajapaksha Prathiraja (Robertson College), Marc Desrosiers/Reena Nerbas/Joan Agdeppa (University of Manitoba)
China --- Gui Wang/Zhou Xu (Hubei University)
Indonesia --- Aulia Putri Srie Wardani (University of Szeged), Helta Anggia (Universitas Bandar Lampung), Irma Zavitri (Hasanuddin University), Rafista Deviyanti (Universitas Lampung), Prihantoro (Universitas Diponegoro)
Korea --- Tecnam Yoon (Chuncheon National University of Education), Wonkyung Choi (Korea University), Byun-Sun Kim (Catholic Kwandong University)
Laos --- Phonesavanh Phanhsavang/Chansouda Siborliboun/Kanokphone Phansavang (Lao-American College), Toulaphone Thoummavong/Thavone Panmanivong/Khambai Phongphachan/Sisoury Phommaseng/Somchay Makesavanh (Souphanouvong University), Ladthamon Khamphilavanh (Chaleun Education Center), Manomay Saysopha (Pakse Teacher Training College)
Pakistan --- Moazzam Ali Malik/Sami Ullah (University of Gujrat), Saira Aftab (University of Lahore)
Philippines --- Arnel Diego/Audrey Eleanor Tong/Jessie Barrot/Jobelle Resuello/Francis August Ramos (National University), Ria de Vera(Ateneo de Manila University)
Taiwan: Yi-ju Ariel Wu/Yen-liang Lin (National Taiwan University), Yungming Yen (Tunghai University)
Thailand --- Ampawan Imaimsup/Arthit Srichandorn/Poraphat Khongsri (Chiang Mai Rajabhat University), Prommin Songsirisak (Chiang Rai Rajabhat University) , Kotchawan Lertchairitthikun (Uppsala University), Phajeekan Harnkaew (Chiang Mai University)
5. Funds
The ICNALE project has been supported by the MEXT (Ministry of Education, Science, Sports and Culture of Japan) / JSPS (Japan Society for the Promotion of Science) Grant-in-Aid for Scientific Research:
No. 23H00641 (From April 2023 to March 2026): Development of the ICNALE Written Essays Plus
No. 17H02360 (From April 2017 to March 2020) : Development of the ICNALE Spoken Dialogue
No. 15K12909 (From April 2015 to March 2018) : Development of the ICNALE Edited Essays
No. 25284104 (From April 2013 to March 2016) : Development of the ICNALE Spoken Monologue
No. 24652120 (From April 2012 to March 2015) : Preparatory research for development of the ICNALE Spoken Monologue
No. 22320104 (From April 2010 to March 2013): Development of the ICNALE Written Essays
6. Citations
Ishikawa, S. (2023). The ICNALE Guide: An Introduction to a Learner Corpus Study on Asian Learners’ L2 English (Routledge).

When using the ICNALE data, please cite this book in your paper.
...................................................................................................................
Former recommended references
(ICNALE Written Essays)
Ishikawa, S. (2013). The ICNALE and sophisticated contrastive interlanguage analysis of Asian learners of English. Learner corpus studies in Asia and the world, 1, 91-118.
(ICNALE Edited Essays)
Ishikawa, S. (2018). The ICNALE edited essays; A dataset for analysis of L2 English learner essays based on a new integrative viewpoint. English Corpus Studies, 25, 117-130.
(ICNALE Spoken Monologue)
Ishikawa, S. (2014). Design of the ICNALE Spoken: A new database for multi-modal contrastive interlanguage analysis. Learner corpus studies in Asia and the world, 2, 63-76.
(ICNALE Spoken Dialogue)
Ishikawa, S. (2019). The ICNALE Spoken Dialogue: A new dataset for the study of Asian learners’ performance in L2 English interviews. English Teaching (The Korea Association of Teachers of English), 74(4), 153-177.
(ICNALE Global Rating Archives)
Ishikawa, S. (2023). Aim of the ICNALE GRA Project : Global Collaboration to Collect Ratings of Asian Learners' L2 English Essays and Speeches from an ELF Perspective. Learner Corpus Studies in Asia and the World, 5, 121-144.
7. Terms of Use
By using the data offered by the ICNALE Development Team, you are agreeing to comply with the Terms of Use. Should you object to any term or condition contained herein, or any subsequent modifications hereto, or become dissatisfied with the ICNALE data in any way, your only recourse is to immediately stop using the ICNALE. The ICNALE Development Team reserve the right, in our sole discretion, to change, modify or otherwise alter these Terms of Use. Such modifications will become effective immediately. You must review these Terms of Use on a regular basis to keep apprised of any changes that may affect you.
(1) The ICNALE Development Team shall not be liable to the user for any trouble, damage or loss caused by his/her use of the ICNALE, regardless of the cause.
(2) The ICNALE Development Team takes utmost care not to make any errors or omissions in providing the data and the information of the ICNALE, however they may include inaccurate contents, typographical errors, or improper information. The ICNALE Development Team shall not be liable for any such inaccuracy, incompleteness, inadequacy and
the unfairness of the data and the information presented in the ICNALE.
(3) The ICNALE Development Team makes no legal warranty or representation regarding the accuracy, completeness, adequacy and fairness of the data and the information of the ICNALE.
(4) The data and the information of the ICNALE may be changed or modified without any prior notice, and the ICNALE Site may be discontinued or closed without any prior notice.
(5) The ICNALE Development Team shall not be liable for any loss caused by the modification of the data and the information and also by the discontinuation or closing of the ICNALE Site, regardless of the reason.
(6) It is prohibited to analyze the interviewer speeches included in the ICNALE Spoken Dialogue.
(7) It is prohibited to reproduce and/or redistribute a part or the whole of the ICNALE data.