ICNALE: The International Corpus Network of Asian Learners of English
A collection of controlled essays and speeches produced by learners of English in 10 countries and areas in Asia
Project Leader: Dr. Shin'ichiro Ishikawa, Kobe University, Japan (iskwshin@gmail.com)
Last updated 2018/4/15
Guide to the ICNALE Online
We offer a quick reference to important technical terms and acronyms used in the ICNALE Online in A-Z order.
Case

You can choose "Insensitive" (is for "is," "Is," "iS," and "IS") or "Sensitive" (is just for "is", Is just for "Is")
Chi2
See Statistics.
CHN
Learners in China. See Participants.
Comparison

You can choose "International" (showing how often a word is used by participants in different countries and areas) or "Domestic/ Proficiency" (showing how often a word is used by learners in a particular country/ area and at different L2 proficiency bands). In the latter case, learners' proficiency levels are automatically limited to B1_2 and B2 only. Please note that the results may become somewhat unstable when the number of learners at those levels is limited.
ENS_others
Ordinary ENS adults living in English-speaking countries. In many cases, they have no experiences teaching English. Their speeches and essays could be regarded as a sample of natural English use. See Participants.
ENS_students
Colleges students in English-speaking countries. When comparing learners, who are all college students, with ENS, it would be best to use ENS_students module. See Participants.
ENS_teachers,
English teachers, instructors, and professors, most of whom work in Japan and have ample experiences teaching English to EFL learners . Generally speaking, their speeches and essays could be regarded as a pedagogical model for ideal English use. See Participants.
HKG
Learners in Hong Kong. See Participants.
IDN
Learners in Indonesia. See Participants.
JPN
Learners in Japan. See Participants.
Lemmatization

You can choose "word form" (play just for "play" and is just for "is") or "lemma" (play for "play," "plays," "played," "playing," and be for "is,""am," "are," "was," "were," "be," "been," "being" etc). By choosing a lemma, you can analyze the vocabulary from a more generalized viewpoint. Meanwhile, if you are interested in the difference between "is" and "was," for example, you should not choose a lemma.
Log-likelihood
See Statistics.
Mutual Information
See Statistics.
Number

The number of the data (concordance lines, word, collocates) to be shown at a time. You can choose from 20, 50, and 100. When you have many hits, you can also download the result directly to your desktop.
PAK
Learners in Pakistan. See Participants.
Participants
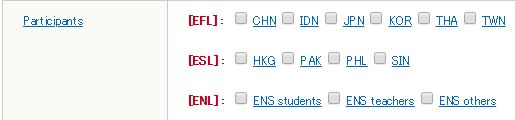
As EFL (English as a Foreign Language) regions, you can choose from six options: CHN (China), IDN (Indonesia), JPN (Japan), KOR (Korea), THA (Thailand), and TWN (Taiwan). And as ESL (English as a Second Language) regions, you can choose from four options: HKG (Hong Kong), PAK (Pakistan), PHL (The Philippines), and SIN (Singapore). Then, as ENL (English as a native language) speaker types, you can choose from three options: ENS students (college students), ENS teachers (NS English teachers mainly working in Japan), and ENS_others (adults having varied job backgrounds). You can choose one or as many as you like in this search setting.
PHL
Learners in the Philippines. See Participants.
POS

POS (parts-of-speech) tagging was conducted on the Sketch Engine System. The grammar rule adopted for tagging is English PennTB-Tree Tagger 2.0.
Production Mode

"Spoken" stands for spoken monologues (NOT dialogues), while "written" stands for written essays.
PTJ
See Topic.
Raw Frequency
See Statistics.
SIN
Learners in Singapore. See Participants.
SMK
See Topic.
Statistics (Collocation Search)

In the results of a collocation search, you can choose one of the four stats and re-sort the important collocates based on it.
"Raw Frequency" is un-adjusted frequency. Syntactic, rather than semantic, collocations (such as "is a" and "think that") tend to be evaluated highly. As raw frequency is subject to corpus size, It is not appropriate to compare the raw frequencies obtained from two corpora of different sizes.
"t score" is originally a statistical value used to judge whether a collocation is statistically significant or not. However, it is also used as a general index showing the strength of collocation. Strictly speaking, significance of collocation and strength of collocation are not the same.
"Log-Likelihood" (aka G2 score) is the statistical value derived from a chi-squared value. Many studies suggest that Log-Likelihood is a well-balanced index when looking for important collocations.
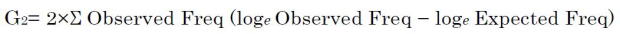
"Mutual Information" (aka MI score) is a statistical value evaluating less frequent but peculiar and unique collocation highly.
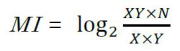
Statistics (Keyword Search)
In the results of a collocation search, you can choose Chi2 or Log-Likelihood (see above) and re-sort the important keywords based on it.
"Chi2" (Chi squared value) is originally used when judging the difference in frequencies is statistically significant or not. A high Chi2 value suggests that a word appears extraordinarily more or less in a target corpus than in a reference corpus.
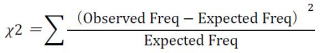
t-score
See Statistics.
Topic

PTJ: "It is important for college students to have a part-time job" and SMK: "Smoking should be completely banned at all the restaurants in the country." Participants were required to show whether they agree or disagree with these statements. They were also required to show the reasons and examples to support their claims.
TWN
Learners in Taiwan. See Participants.
Word(s)
You can enter a single word or a sequence of words. You can also use a POS code. If you like to search either of A or B, you should enter "A|B." If you enter the search string of I|We [v*] that, you will receive the results of "I think that," "I suppose that," "We saw that" etc. See POS.