ICNALE: The International Corpus Network of Asian Learners of English
A collection of controlled essays and speeches produced by learners of English in 10 countries and areas in Asia
Project Leader: Dr. Shin'ichiro Ishikawa, Kobe University, Japan (iskwshin@gmail.com)
Last updated 2026/3/4
The ICNALE Main Modules
| Modules | Version | Updated | # of participants | # of samples | # of words |
| Spoken Monologues (SM) | V2.1 | 2023/6 | 1,100 | 4,400 | 500,000 |
| Spoken Dialogues (SD) | V1.4 | 2023/6 | 425 | 4,250 | 1,600,000 |
| Written Essays (WE) | V2.6 | 2025/1 | 2,800 | 5,600 | 1,300,000 |
| Edited Essays (EE) | V3.1 | 2023/6 | 328 | 1,312 | 150,000 |
| Written Essays Plus (WEP) | V0.7 | 2026/3 | 1,170 | 3,340 | 570,000 |
| --- Learner Outputs Total--- | --- | --- | 5,601 | 17,458 | 3,798,000 |
| Global Rating Archives (GRA) | V2.1 | 2024/03 | 280 samples X 80 raters | 22,400 | (Edited essays) 32,000 |
+New Module Notation Rule (Revised in September 2021)
Eg., "ICNALE Spoken Monologues" or "ICNALE Spoken Monologue Module"
When adding "Module" at the end, use the singular forms as in "Monologue Module" or "Dialogue Module"; otherwise use the plural forms as in "Monologues" or "Dialogues."
+ New Sub-folder Structures (Adopted in June 2023)
0: Unclassified_Unmerged
1: Classified_Unmerged
2: Classified_Merged
3: Classified_Merged_Tagged
ICNALE readme.txt
+ New Tagged Data Format (Adopted in June 2023)
(Was): vert -> (Now): txt
+New name rules for merged and tagged files(Adopted in January 2025)
XXX_mg.txt
YYY_mg_tg.txt
Also, a tag guide has been included in the tag folders.
1. ICNALE Spoken Monologues
About
The ICNALE Spoken Monologues is a collection of learners' 60-seconds monologues about two ICNALE common topics ("a part-time job for college students" and "non-smoking at restaurants"). Each participant made five 60-seconds speeches on the answering phone: (1) Self introduction, (2) First speech about the part-time job, (3) Second speech about the part-time job, (3) First speech about the non-smoking, and (4) Second speech about the non-smoking. The data (2) - (4) are collected in the corpus. They were given a 20-seconds preparation time before the first speech, and then a 10-second preparation time before the second speech. They were told to speak as much as possible. The audio data and transcripts are included in the corpus.
Size
The ICNALE Spoken Monologues includes 4,400 speech samples (approximately 73 hours of recording) by 1,100 participants. The total number of tokens is approximately 500,000.
Participants and Samples
1,100 participants/ 4,400 samples in four subsets: PTJ1, PTJ2, SMK1, SMK2
| [SM] | A2 | B11 | B12 | B2+ | Sum |
| CHN | 14 | 48 | 78 | 10 | 150 |
| HKG | X | 1 | 23 | 26 | 50 |
| IDN | 26 | 37 | 34 | 3 | 100 |
| JPN | 30 | 47 | 43 | 30 | 150 |
| KOR | 6 | 15 | 43 | 36 | 100 |
| PAK | 5 | 6 | 88 | 1 | 100 |
| PHL | X | 7 | 81 | 12 | 100 |
| SIN | X | X | 29 | 21 | 50 |
| THA | 2 | 19 | 25 | 4 | 50 |
| TWN | 17 | 41 | 25 | 17 | 100 |
| ENS | X | X | X | X | 150 |
| Total | 100 | 221 | 469 | 160 | 1100 |
History
Development of The ICNALE Spoken Monologues began in 2015, and ended in 2018.
Updates
The ICNALE Spoken Monologues V2.1 (2023 June)
Folder structure has been changed. Unmerged_Unclassified Folder has been added.
The audio file distribution method has been changed.
(Was) As a zipped file
(New) Link to Google Drive
The ICNALE Spoken Monologues V2.0 (2017 August)
Module name has been changed from “Spoken” to “Spoken Monologue”
File names are also changed from S to SM.
Data itself is NOT changed.
Distribution of “The ICNALE-SW” package has been terminated, meaning Speaking Monologue and Written Essays are to be distributed separately.
The ICNALE-Spoken V 1.2 (2015 December) As a part of the ICNALE-SW 1.1
[Data Addition and correction]
Data of 41 learners in PAK have been added (PAK060-100).
30 data (PAK060-089) have been collected in the ICNALE Automatic Speech Collection System; and the remaining 11 data (PAK090-100) have been collected in the computer lab under the supervision of the local co-researcher.
Corrected several typos and inconsistencies in the Info sheet (e.g. Science/ Sciences ---> Sciences)
The ICNALE-Spoken V 1.1 (2015 October) As a part of the ICNALE-SW 1.0
[Data Addition and correction]
Data of 50 learners in JPN have been added (JPN101-150).
Data of 75 English native speakers (ENS) have been added (ENS 76-150).
Data of the PAK_001 to 050, which was collected in the computer lab unlike other modules, have been replaced with new data, which was newly collected in the ICNALE Automatic Speech Collection System.
Speeches and transcripts by IDN_086 have been replaced with correct ones.
[Code]
A new code system has been adopted.
(Ex.) S_CHN_PTJ1_001_B1_1 (The first speech about part-time job by Chinese learners #001, whose CEFR-proficiency level is B1 lower.)
W_CHN_PTJ0_001_B1_1 (The essay about part-time job by Chinese learners #001, whose CEFR-proficiency level is B1 lower.)
NB: Participants in the ICNALE-Spoken and in the ICNALE-Written are different.
[Data Classification]
ENS data have been separated into three groups: XX_1: College students (incl. grad students), XX_2: English Teachers, XX_3: Others.
[MP3]
Corrected the typos in the filename of the wav files of a CHN001 learner.
Deleted the wrongly duplicated files.
Corrected the errors in the filenames of SIN_010-019
[Info Sheet]
Corrected the typos (“ENG” to “ENS”. “UK” to “GBR”)
The column of “ENS Types” have been added.
The columns of “Total # of tokens” and “Ratio of Trial 1 to Trial 2” have been deleted.
The column of “country” have been moved.
The tokens in the speeches have been corrected. This is due to the text data clarification mentioned below.
[Text cleaning for speech transcripts]
Corrected character corruptions
Replaced “a^” with apostrophes and dashes
Replaced “S’ ” and “c” at the end of the sentence with hyphens
Replaced “f” (Eg: fs, fd, ft) with apostrophes
Replaced unclarity tags ([Unclear] [Technical Difficulty] [ph]) with [***]
Replaced foreign language tags ([Foreign Language] [Japanese]) with [****]
[Distribution]The ICNALE-Spoken and the ICNALE-Written integrated into the ICNALE-SW.
The ICNALE-Spoken V1.0 (2015 May)
Data of 100 KOR learners was added (KOR_001 --- KOR_100)
Data of 50 HKG learners was added (HKG_001 --- HKG_050)
Data of 50 THA learners was added (THA_001 --- THA_050)
“The years of studying English” column in the Speakers’ info sheet was omitted because it was proven that not a few students misunderstood the question.
The ICNALE-Spoken Baby V1.3 (2014 December)
Data of 100 CHN learners was added. (CHN_051---CHN_150)
Data of 50 TWN learners was added (TWN_051---TWN_100)
Data of 100 IDN learners was added (IDN_001---IDN_100)
Corrected errors in the academic genres of some Japanese learners (the info sheet)
Wrongly duplicated files in the ENS module in the “Transcript Classified” Folder was deleted
“Transcript_ Classified” Folder was added to Baby 1.3
The ICNALE-Spoken Baby V1.2 (2014 September)
Corrected coding errors in academic genres in the speaker’s info sheet.
Data of 50 PAK learners was added.
Data of 25 ENS speakers was added. (NES_051---ENS_075)
Data of 50 SIN learners was added.
The ICNALE-Spoken Baby V1.1 (2014 July)
Corrected proficiency levels of JPN_021, and CHN_043
Data of 50 JPN learners was added. Data of 50 PHL learners was added.
The ICNALE-Spoken Baby V1.0 (2014 May)
Distributed the data of 1,000 speech samples (ENS, CHN, JPN, TWN, PHL)
2. ICNALE Spoken Dialogues
About
The ICNALE Spoken Dialogues is a collection of learners' and teachers' (namely, interviewers') utterances in 30-40-minutes semi-structured oral interviews. They include ten kinds of tasks: Introduction, Picture Description (PD) 1, PD1-related QA, Role-play (RP) 1, RP1-related QA, PD2, PD2-related QA, RP 2, RP2-related QA, and Reflection). All the tasks are related to the ICNALE common topics ("a part-time job for college students" and "non-smoking at restaurants"). The corpus includes both videos and transcripts.
Size
425 speakers (405 learners plus 20 English native speakers) jointed the interviews. The corpus includes approx. 270-hour videos and approx. 1,600,000-words transcripts.
Participants and Samples (As of November 2021)
425 speakers and 4,250 samples
| [SD] | A2 | B11 | B12 | B2+ | Sum |
| CHN | 3 | 11 | 17 | 19 | 50 |
| HKG | X | 10 | 9 | 11 | 30 |
| IDN | 6 | 6 | 16 | 2 | 30 |
| JPN | 31 | 29 | 28 | 12 | 100 |
| KOR | X | 3 | 7 | 10 | 20 |
| MYS | 2 | 4 | 14 | X | 20 |
| PAK | 5 | 6 | 13 | 1 | 25 |
| PHL | 1 | 1 | 34 | 4 | 40 |
| THA | 7 | 12 | 19 | 2 | 40 |
| TWN | 11 | 7 | 16 | 16 | 50 |
| ENS | X | X | X | X | 20 |
| Total* | 66 | 89 | 172 | 78 | 425 |
History
Development of The ICNALE Spoken Dialogue began in 2018, and it was completed in March 2020.
Updates
The ICNALE Spoken Dialogues V1.4' (2024 August)
We have found that the student's voice of the TWN_011 video was partially cut-off (between 12'22'' and 29'10'') and some tasks were not recorded appropriately in the TWN_015 video. Therefore, we added the notes and uploaded the audio files (TWN_011_audio and TWN_015_audio).
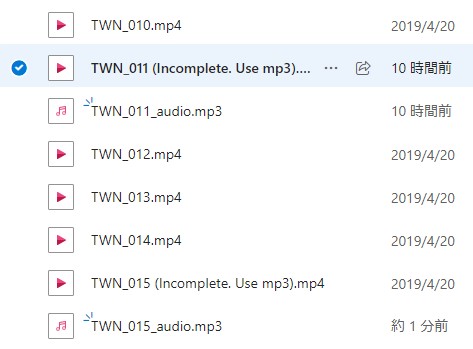
The ICNALE team thanks Dr. Pham Quy for identifying this issue. As no data is altered, the version number is unchanged.
The ICNALE Spoken Dialogues V1.4 (2023 June)
File names have been renewed.
Folder structure has been changed. Unmerged_Unclassified Folder has been added.
Tagged data has been added.
The ICNALE Spoken Dialogues V1.3 (2021 November)
1) The proficiency level of KOR_016 was corrected (B2 --> B1_2)
2) The data of Proficiency and Sex of learners in Korea and Malaysia, which was missing in the V1.2, was newly added in the transcript sheet of the Excel file.
N.B. No changes in the videos and transcripts.
The ICNALE Spoken Dialogues V1.2 (2021 September)
(1) Correction of the errors in the table of the participants and samples
(2) Addition of two folders: Classified + Merged
N.B. No changes in the videos and transcripts.
The ICNALE Spoken Dialogues V1.1 (2021 March)
(1) Correction of the errors in the speaker background info
Genders and Proficiency levels of CHN_001-024 and KOR_016 were appropriately corrected.
(2) Change in the type of the distributed data
V1.1 includes the data below:
ICNALE SD 1.1 Data Sheet.xlsx --- Speaker Info, Transcripts, & Related Stats
ICNALE SD 1.1 Speaker Utterances (N=4250) ---A collection of speaker utterances (Excl. Interviewer’s utterances)
ICNALE SD 1.1 Video URL
N.B. No changes in the videos and transcripts.
The ICNALE Spoken Dialogues V1.0 (2020 March)
(1) Task-based utterance files have been added (425 persons X 10 tasks = 4,250 files). Related stat data has been added.

(2) Errors in task codes have been corrected.
CHN021_01
IDN002_03
IDN009_06
IDN010_09
IDN025_09
PAK002_03
PAK003_09
THA005_03/ 12
THA006_09
THA007_04
THA009_09
THA010_09
THA015_09
NB: Most of the errors were seen in the transitions from a picture description (No. 3/9) to its related QA (No. 4/10).
(3) It was found that two tasks were skipped by interviewers. Notes have been added.
KOR015_07 (PTJ_RP_QA Task)
PHL002_14 (Reflection Task)
NB: As no new data has been added, the version number remains the same (1.0).
The ICNALE Spoken Dialogues V1.0 (2019 December)
The ICNALE SD V1.0 includes the data of 425 speakers.
+ We have decided not to distribute "merged" files any more.
+ Turn codes have been corrected (CHN_024, 028; PAK_02 08; KOR_04, 07; HKG_016, 020, 023, 026; PHL_018; JPN_089).
The ICNALE Spoken Dialogues V0.9 (2019 August)
The ICNALE SD Baby was upgraded to The ICNALE SD V0.9, which includes the data of 385 speakers in 8 countries and regions in Asia.
(1) The data of the students in China and Pakistan was newly added. Also, the data of the students in Taiwan increased.
A2 B1_1 B1_2 B2+ Total
ENS NA NA NA NA 20
CHN* 2 13 17 18 50
JPN 31 29 28 12 100
IDN 6 6 16 2 30
THA 7 12 19 2 40
TWN 11 7 16 16 50
HKG X 10 9 11 30
PAK 5 6 13 1 25
PHL 1 1 34 4 40
Total 63 84 152 66 385
NB*: The Chinese sub-module includes the data of (a) 25 students studying in Japan and (b) the same number of students studying in the mainland China. Follow-up interviews were done in Japanese for the type (a) students and in Chinese for the type (b) students.
(2) Change in the way to distribute video data
As the total file size reached approx. 300GB, we decided to upload individual files rather than a single zipped file.
The ICNALE Spoken Dialogues Baby V0.3 (2019 April)
The Baby V0.3 includes the data of 285 speakers shown below:
A2 B1_1 B1_2 B2+ Total
ENS N/A N/A N/A N/A 20
JPN 31 29 28 12 100
IDN 6 6 16 2 30
THA 7 12 19 2 40
TWN 1 5 9 10 25
HKG X 10 9 11 30
PHL X 1 34 4 40
Total 45 63 115 41 285
1) The data of 25 Chinese students and 25 Taiwanese students, which is now in the transcribing process, will be added soon.
2) Sound files are in the mp3 format. Sound Quality: “MPEG1-LayerIII 44.10kHz 128.00kb”
3) The ICNALE Team has not decided how to distribute the movie files, whose size is expected to be larger than 10GB. We will decide it in a due time.
4) We finished task coding only for the data of English native speakers and Japanese learners. No task codes are not given to other participants.
5) L1 reflection data has NOT been distributed yet.
The ICNALE Spoken Dialogues Baby V0.2 (2018 May)
The Baby V0.2 includes the transcripts of 100 Japanese college students& utterances in the oral interviews.
1) Three interviews were added (Participant 98, 99, 100)
2) As it was shown that the interview with the participant 002 was NOT recorded appropriately, we replaced it with a different interview. (The 002 participant was at B1_1 level before, but it is now at B2_0 level)/
3) The [E] codes (meaning “examinees”) in the text files were replaced by the [S] codes (meaning “students”).
4) V0.2 is used for the ICNALE Online.
The ICNALE Spoken Dialogues Baby V0.1 (2018 April)
The Baby V0.1 includes the transcripts of 97 Japanese college students& utterances in the oral interviews.
3. ICNALE Written Essays
About
The ICNALE Written Essays is a collection of learners' 200-to-300-words essays about two ICNALE common topics ("a part-time job for college students" and "non-smoking at restaurants"). Learners were given 20-40 minutes to write one essay. They wrote essays on MS Word (R). Use of a spell-checker was allowed, but use of references was prohibited.
Size
The ICNALE Written Essays includes 5,600 essays written by 2,800 participants. Its size is approximately 1,300,000 words.
Participants and Samples
2,800 participants/ 5,600 samples in two subsets: PTJ and SMK
| [WE] | A2 | B11 | B12 | B2+ | Sum |
| CHN | 50 | 232 | 105 | 13 | 400 |
| HKG | 1 | 30 | 52 | 17 | 100 |
| IDN | 32 | 82 | 83 | 3 | 200 |
| JPN | 154 | 179 | 49 | 18 | 400 |
| KOR | 75 | 61 | 88 | 76 | 300 |
| PAK | 18 | 91 | 88 | 3 | 200 |
| PHL | 2 | 11 | 176 | 11 | 200 |
| SIN | X | X | 134 | 66 | 200 |
| THA | 119 | 179 | 100 | 2 | 400 |
| TWN | 29 | 87 | 61 | 23 | 200 |
| ENS | X | X | X | X | 200 |
| Total | 480 | 952 | 936 | 232 | 2800 |
History
Development of The ICNALE Written Essays began in 2007, and ended in 2013. The Corpus was formerly called CEEAUS (Corpus of English Essays by Asian University Students).
Updates
The ICNALE Written Essays V2.6 (2024 January/ 2025/January)
(1) Anonymization: College names remaining in several essays have been masked with ***. (20 in total; 7 in PHL, 4 in CHN, 6 in THA, and 1 in SIN, IDN, and JPN )
(2) Inappropriately encoded files have been corrected (CHN_PTJ_006/008, THA_PTJ_266, THA_SMK_357, TWN_PTJ_047, TWN_SMK_056)
(3) Identified two problematic files (KOR_PTJ_062/063/200: These students may have not understood the topic appropriately)
(4) Merged files have been re-created.
(5) All the merged files have been newly tagged with English 3.3 for Tree Tagger pipeline v2 on Sketch Engine.
________________________
(2025/January, Updated)
Added the tagged data of ENS_XX3_SMK, which was missing in the past release. The file name was renamed from "alltagged" to "WE_all_tagged."
The ICNALE Written Essays V2.5 (2023 June)
Folder structure has been changed.
File names have been slightly changed. "W_" has been changed into "WE_" for consistency.
The ICNALE Written Essays V2.4 (2019 April --> Public Release in 2020 December)
(1) Replaced the CHN_PTJ0_A2 merge file (both text and vert), which included duplicated essays with new files.
(2) Added the info about inappropriate essays to the readme file.
(a) PTJ essays by THA_284 and THA_400 were found to be almost identical.
(b) SMK essays by JPN_123 and JPN_396 were also found to be identical.
(c) PTJ and SMK essays by JPN_093 included the duplicated passages.
The ICNALE Written Essays V2.3’ (2018 April)
Notes (2018, January)
(1) The version number shown in several folders was corrected: 2.0 -> 2.3
(2) The Philippines’s three-letter country codes shown in several folders were corrected: “PHR” -> “PHL”
Additional Note: It was found that the final sentence of the essay coded as “W_CHN_PTJ0_391_A2_0.txt,” which ended with “…it will give us what,” was not completed appropriately (Some words may drop). However, as the author seems to have fully developed his/her ideas, we have deiced not to replace this file with a different data.
The ICNALE Written Essays V2.3 (2017 August)
Module name has been changed: “Written” to “Written Essays”
Data itself is NOT changed.
Distribution of “The ICNALE-SW” package has been terminated, meaning Speaking Monologue and Written Essays are to be distributed separately.
The ICNALE-Written V2.2 (2015 October) As a part of the ICNALE-SW 1.0
[Code]
A new code system has been adopted.
(Ex.)
S_CHN_PTJ1_001_B1_1 (The first speech about part-time job by Chinese learners #001, whose CEFR-proficiency level is B1 lower.)
W_CHN_PTJ0_001_B1_1 (The essay about part-time job by Chinese learners #001, whose CEFR-proficiency level is B1 lower.)
NB: Participants in the ICNALE-Spoken and in the ICNALE-Written are different.
[Data Classification]
ENS data have been separated into three groups: A: Learners, B: Teachers, C: Others.
The ICNALE-Written V2.1 (2013 February)
Errors in two merged files, “CHN_B11_PTJ_01.txt” and “CHN_B11_SMK_01.txt,” and their tagged files have been corrected. No changes are made with other files.
The ICNALE-Written V2.0 (2013 January)
Singapore data was added
C2 level was integrated into B2+ level
"Category" folder was deleted
The ICNALE-Written V1.3 (2012 October)
Wrongly duplicated files were replaced
The number of types and tokens were recalculated with Wordsmith
"Category" folder was added
The ICNALE-Written V1.2 (2012 August)
Philippine data was added
The ICNALE-Written V1.1 (2012 August)
2-bytes characters were replaced
The ICNALE-Written V1.0 (2012 April)
The download version was released.
…………………………………………………………………………………………….
Corpus of English Essays by Asian University Students (CEEAUS) (2008 December)
Prior to the ICNALE Project, we released a small corpus called CEEAUS, which contains:
1) CEEJUS: Corpus of English Essays Written by Japanese University Students (770 essays)
2) CEECUS: Corpus of English Essays Written by Chinese University Students (92 essays)
3) CEENAS: Corpus of English Essays Written by Native Speakers (146 essays)
4) CJEJUS: Corpus of Japanese Essays Written by Japanese University Students (50 essays)
The ICNALE Written Essays includes a part of the data collected in the CEEJUS project.
3' ICNALE Written Essays Plus (Ongoing project since 2023)
About
The ICNALE Written Essays Plus (WEP) is a collection of 200-to-300-word essays about two ICNALE common topics ("a part-time job for college students" and "non-smoking at restaurants"). The data is now being collected from the countries that have not been covered in the previous ICNALE projects, including Bangladesh, Cambodia, India, Malaysia, Myanmar, Nepal, Vietnam, and more.
Notes
Access to online writing support tools, including Deep L, Google Translator, and Chat GPT, has become quite common in comparison to the 2000s–2010s when the original ICNALE Written Essay Module was developed. In order to collect comparable data, the ICNALE team required all the participants to explicitly declare that they had not used any of those tools when writing. However, as many students write at home, it is not wholly guaranteed that such a tool does not influence their writing at all. The ICNALE team, therefore, has decided to release the newly collected essay data as an independent module (ICNALE WEP) rather than as a part of the ICNALE WE.
Size
The ICNALE Written Essays Plus (WEP) v0.7 includes 3,340 essays written by 1,170 participants from eleven countries. Its size is approximately 570,000 words.
The ICNALE Written Essays Plus V0.7 (2026 March)
Participants and Samples
| [WEP] | A2 | B11 | B12 | B2+ | Sum |
| BGD | 1 | 1 | 72 | 27 | 101 |
| BRN | 0 | 1 | 37 | 12 | 50 |
| IND | 1 | 16 | 78 | 96 | 191 |
| KHM | 1 | 24 | 26 | 1 | 52 |
| LAO | 8 | 14 | 18 | 0 | 40 |
| MYS | 1 | 15 | 80 | 11 | 107 |
| MMR | 4 | 55 | 60 | 13 | 132 |
| NPL | 1 | 10 | 36 | 3 | 50 |
| VNM | 67 |
118 |
87 |
166 |
438 |
| (MNG) | 0 | 0 | 4 | 2 | 6 |
| (LKA) | 0 | 0 | 0 | 3 | 3 |
| Ttl | 84 |
254 |
498 |
334 |
1,170 |
・16 Vietnamese students' CEFR levels have been appropriately corrected.
Old Code Correct Level
(Former Level: A2)
WEP_VNM_236 A2_0 B1_1
WEP_VNM_292 A2_0 B1_1
WEP_VNM_392 A2_0 B1_1
WEP_VNM_395 A2_0 B1_1
(Former Level: B11)
WEP_VNM_227 B1_1 B1_2
WEP_VNM_258 B1_1 B1_2
WEP_VNM_267 B1_1 A2_0
WEP_VNM_301 B1_1 B1_2
WEP_VNM_311 B1_1 B1_2
WEP_VNM_397 B1_1 B1_2
WEP_VNM_418 B1_1 B1_2
WEP_VNM_430 B1_1 B1_2
(Former Level B12)
WEP_VNM_359 B1_2 B2_0
WEP_VNM_415 B1_2 B2_0
WEP_VNM_417 B1_2 B2_0
(Former Level B2)
WEP_VNM_285 B2_0 B1_2
___________________________________________
History
The ICNALE Written Essays Plus V0.6 (2026 January)
Participants and Samples
| [WEP] | A2 | B11 | B12 | B2+ | Sum |
| BGD | 1 | 1 | 72 | 27 | 101 |
| BRN | 0 | 1 | 37 | 12 | 50 |
| IND | 1 | 16 | 78 | 96 | 191 |
| KHM | 1 | 24 | 26 | 1 | 52 |
| LAO | 8 | 14 | 18 | 0 | 40 |
| MYS | 1 | 15 | 80 | 11 | 107 |
| MMR | 4 | 55 | 60 | 13 | 132 |
| NPL | 1 | 10 | 36 | 3 | 50 |
| VNM | 70 |
122 |
82 |
164 |
438 |
| (MNG) | 0 | 0 | 4 | 2 | 6 |
| (LKA) | 0 | 0 | 0 | 3 | 3 |
| Ttl | 87 |
258 |
493 |
332 |
1,170 |
・VNM data (No. 217-438) has been added.
The ICNALE Written Essays Plus V0.5 (2025 October)
Participants and Samples
| [WEP] | A2 | B11 | B12 | B2+ | Sum |
| BGD | 1 | 1 | 72 | 27 | 101 |
| BRN | 0 | 1 | 37 | 12 | 50 |
| IND | 1 | 16 | 78 | 96 | 191 |
| KHM | 1 | 24 | 26 | 1 | 52 |
| LAO | 8 | 14 | 18 | 0 | 40 |
| MYS | 1 | 15 | 80 | 11 | 107 |
| MMR | 4 | 55 | 60 | 13 | 132 |
| NPL | 1 | 10 | 36 | 3 | 50 |
| VNM | 10 | 44 | 39 | 123 | 216 |
| (MNG) | 0 | 0 | 4 | 2 | 6 |
| (LKA) | 0 | 0 | 0 | 3 | 3 |
| Ttl | 27 | 180 | 450 | 291 | 948 |
・VNM data (No. 120-216) has been added.
・Proficiency levels of VNM_051, VNM_078, and NPL_039 have been corrected.
---> 2025/10: Corrected the inappropriate filenames (e.g., _mg,.txt) of the texts included in the merge data folder. Data has NOT been changed.
The ICNALE Written Essays Plus V0.4 (2025 June)
Participants and Samples
851 participants/ 1,702 samples in two subsets: PTJ and SMK
| [WEP] | A2 | B11 | B12 | B2+ | Sum |
| BGD | 1 | 1 | 72 | 27 | 101 |
| BRN | 0 | 1 | 37 | 12 | 50 |
| IND | 1 | 16 | 78 | 96 | 191 |
| KHM | 1 | 24 | 26 | 1 | 52 |
| LAO | 8 | 14 | 18 | 0 | 40 |
| MYS | 1 | 15 | 80 | 11 | 107 |
| MMR | 4 | 55 | 60 | 13 | 132 |
| NPL | 1 | 10 | 37 | 2 | 50 |
| VNM | 7 | 30 | 14 | 68 | 119 |
| (MNG) | 0 | 0 | 4 | 2 | 6 |
| (LKA) | 0 | 0 | 0 | 3 | 3 |
| Ttl | 24 | 166 | 426 | 235 | 851 |
(2) Nepal data was newly added.
(3) Merged files (mg) are now included in the data folders.
The ICNALE Written Essays Plus V0.3 (2024 October)
Participants and Samples
630 participants/ 1,260 samples in two subsets: PTJ and SMK
| [WEP] | A2 | B11 | B12 | B2+ | Sum |
| BGD | 1 | 1 | 72 | 26 | 100 |
| BRN | 0 | 1 | 37 | 12 | 50 |
| KHM | 1 | 24 | 24 | 1 | 50 |
| IND | 1 | 4 | 15 | 90 | 110 |
| LAO | 8 | 14 | 18 | 0 | 40 |
| MYS | 1 | 14 | 74 | 11 | 100 |
| MMR | 4 | 54 | 59 | 13 | 130 |
| VNM | 6 | 16 | 11 | 17 | 50 |
| Ttl | 22 | 128 | 310 | 170 | 630 |
(1) Data of students from IND and LAO have increased. (N=600 -> 630)
(2) The proficiency level of LAO_034 was corrected from B2_0 to B1_2.
(3) The writer groups of <10 participants were excluded from the Classified folder.
The ICNALE Written Essays Plus V0.2 (2024 September)
Participants and Samples
600 participants/ 1,200 samples in two subsets: PTJ and SMK
| [WEP] | A2 | B11 | B12 | B2+ | Sum |
| BGD | 1 | 1 | 72 | 26 | 100 |
| BRN | NA | 1 | 37 | 12 | 50 |
| IND | 1 | 4 | 14 | 66 | 85 |
| KHM | 1 | 24 | 24 | 1 | 50 |
| LAO | 4 | 14 | 16 | 1 | 35 |
| MMR | 4 | 54 | 59 | 13 | 130 |
| MYS | 1 | 14 | 74 | 11 | 100 |
| VNM | 6 | 16 | 11 | 17 | 50 |
| Ttl | 18 | 128 | 307 | 147 | 600 |
(2) Module name was changed from "Written Essays 2" to "Written Essays Plus."
The ICNALE Written Essays 2 V0.1 (2024 April)
Participants and Samples
500 participants/ 1,000 samples in two subsets: PTJ and SMK
| [WE2] | A2 | B11 | B12 | B2+ | Sum |
| BGD | 1 | 1 | 72 | 26 | 100 |
| KHM | 1 | 24 | 24 | 1 | 50 |
| IND | 1 | 4 | 14 | 66 | 85 |
| LAO | 4 | 14 | 16 | 1 | 35 |
| MYS | 1 | 14 | 74 | 11 | 100 |
| MYM | 4 | 54 | 59 | 13 | 130 |
| Ttl | 12 | 111 | 259 | 118 | 500 |
(2) All the merged files have been tagged with en-core-web-sm-3.2.4.
4. ICNALE Edited Essays
About
The ICNALE Edited Essays is a collection of edited versions of learner essays about two ICNALE common topics ("a part-time job for college students" and "non-smoking at restaurants"), which were taken from the ICNALE Written Essays. Professional editors edited learners' original essays so that they became fully intelligible, though changing the content was prohibited. This module also includes the rubric-based evaluation (rating) of learner essays.
Size
The ICNALE Edited Essays includes 656 edited versions of the essays originally written by 328 participants. The total number of tokens is approximately 150,000. The corpus also includes the same amount of original essays, which are a part of the ICNALE Written Essays.
Participants and Samples
328 participants / 656 original essays + 656 edited essays
| [EE] | A2 | B11 | B12 | B2+ | Sum |
| CHN | 10 | 10 | 10 | 10 | 40 |
| HKG | X | 10 | 10 | 10 | 30 |
| IDN | 10 | 10 | 10 | 3* | 33 |
| JPN | 10 | 10 | 10 | 10 | 40 |
| KOR | 10 | 10 | 10 | 10 | 40 |
| PAK | X | 10 | 10 | 3* | 23 |
| PHL | X | 10 | 10 | 10 | 30 |
| SIN | X | X | 10 | 10 | 20 |
| THA | 10 | 10 | 10 | 2* | 32 |
| TWN | 10 | 10 | 10 | 10 | 40 |
| ENS | X | X | X | X | X |
| Total | 60 | 90 | 100 | 78 | 328 |
History
Development of The ICNALE Edited Essays began in 2015, and ended in 2018. The Corpus was formerly called The ICNALE Proofread.
Updates
The ICNALE Edited Essays V3.1 (2023 June)
Folder structure has been changed.
The ICNALE Edited Essays V3.0 (2023 March)
Code errors were corrected
(1) In the EE_Unmerged_Unclassified Folder and EE_Unmerged Classified Folder
(Wrong) W_CHN_PTJ0_272_B2_0_EDIT.txt
(Correct) W_CHN_PTJ0_277_B2_0_EDIT.txt
(2) Infosheet (ICNALE EE)
Line 40, Column A
(Wrong) W_CHN_PTJ0_272_B2_0_EDIT.txt --> (Correct) W_CHN_PTJ0_275_B2_0_EDIT.txt
Line 41, Column A
(Wrong) W_CHN_PTJ0_275_B2_0_EDIT.txt ---> (Correct) W_CHN_PTJ0_277_B2_0_EDIT.txt
NB: No change in the version number.
The ICNALE Edited Essays V3.0 (2022 April)
The data of 8 learners at B2 level in Pakistan (3 psns), Thailand (2 psns), and Indonesia (3 psns) have been added.
The ICNALE Edited Essays V2.1 (2018 July)
(1) Encoding errors were corrected.
It was found that three files of edited essays included coding errors (dashes and French “e” in the texts were inappropriately changed into the mark “�”). These were appropriately corrected. (Both of individual files and merged files)
Corrected files (3 files)
KOR_PTJ_075_B2_0, KOR_SMK_017_B1_1, TWN_PTJ_069_B2_0
(2) Inappropriate merged files were replaced.
It was found that 11 kinds of PTJ merged files (both of tagged/vert and untagged/txt), which were newly added or updated in April 2018, included both of the part-time job and non-smoking essays. These were replaced by correct files. Also, the related SMK merged files were added.
Wrong merged files in Version 2.0
HKG_PTJ_B1_1; KOR_PTJ_A2_0/ B1_1/ B2_0; THA_PTJ_A2_0/ B1_1; PHL_PTJ_B1_1; PAK_PTJ_B1_1
(3) Folder structure was simplified.
V2.0
Unmerged_Original_classified
Unmerged_Original_individual
Unmerged_Edited_classified
Unmerged_Edited_individual
Unmerged_Edited_individual_doc
Merged_Plain Text
Merged_Tagged
V2.1
Unmerged_Classified
Unmerged_Unclassified
Merged
(4) The typos in the learner info sheet were corrected.
The scores for “Fair to Poor” are NOT “03~06” but “04-06.”
The ICNALE Edited Essays V2.0 (2018 April)
320 participants / 1280 samples in four subsets: PTJ_original, PTJ_edited, SMK_original, and SMK_edited
| [EE] | A2 | B11 | B12 | B2+ | Sum |
| CHN | 10 | 10 | 10 | 10 | 40 |
| HKG | X | 10 | 10 | 10 | 30 |
| IDN | 10 | 10 | 10 | X | 30 |
| JPN | 10 | 10 | 10 | 10 | 40 |
| KOR | 10 | 10 | 10 | 10 | 40 |
| PAK | X | 10 | 10 | X | 20 |
| PHL | X | 10 | 10 | 10 | 30 |
| SIN | X | X | 10 | 10 | 20 |
| THA | 10 | 10 | 10 | X | 30 |
| TWN | 10 | 10 | 10 | 10 | 40 |
| ENS | X | X | X | X | X |
| Total | 60 | 90 | 100 | 70 | 320 |
(1) Added the B1 learner data in Hong Kong, Pakistan, and the Philippines.
Table . The number of original essays in the ICNALE Edited Essays V2.0
Code A2 B1_1 B1_2 B2+ Total
CHN 20 20 20 20 80
JPN 20 20 20 20 80
IDN 20 20 20 60
KOR 20 20 20 20 80
THA 20 20 20 60
TWN 20 20 20 20 80
HKG 20 20 20 60
PAK 20 20 40
PHL 20 20 20 60
SIN 20 20 40
Total 120 180 200 140 640
(2) Corrected the coding errors
It was found that the edited texts included several coding errors (apostrophes -> “f”; open double quotation marks -> “g”, close double quotation marks -> “h”). These were corrected appropriately corrected.
Corrected files (7 files)
[Individual] KOR: PTJ_031(A2); SMK_003(B11)/ 004(B2)/ 008(B11)/ 056(B2) THA: PTJ_030(B11); SMK_014(A2)
[Merged] KOR_A2, KOR_B11, KOR_B2, THA_A2, THA_B11
(3) Calibration data set has been released.
Five editors participated in the project and they were required to rate and edit eight common essays. You can investigate the inter/ intra- rater reliability by scrutinizing the calibration data.
The ICNALE Edited Essays V1.1 (2018 January)
(1) Changed the internal structure of the Merged Folder for consistency
+ Deleted a folder of “Country_Classified”
(2) Corrected errors on the Infosheet
+ File Names
Wrong: W_JPN_PTJ0_003_B2_0_EDIT.txt
Correct: W_JPN_PTJ0_004_B2_0_EDIT.txt
+ Weights on the five criteria in essay evaluation
Wrong: Contents (30), Organization (20), Vocabulary (20), Language Use (20), Mechanics (5)
Correct: Contents (30), Organization (20), Vocabulary (20), Language Use (25), Mechanics (5)
+ Total 2 (Weighted %)
Accordingly, we corrected the values given as Total 2 (Weighted %) in the Infosheet.
Why Total 2 (Weighted %) was changed Firstly, we conducted calculation of the total score based on the category weights shown in the file of “Appendix 9.12 ESL Composition Profile” obtained from http:// thandbool.heinle.com, which gave 20 points to “Language Use.” However, we were informed that 25 points should be given to “Language Use” by reading the original rubric (Jacobs, et al., 1981). Sorry for any inconvenience that this may have caused.
The ICNALE Edited Essays V1.0 (2017 August)
The data of learners in HKG, PAK, PHL, and SIN were added.
Table . The number of original essays in the ICNALE Edited Essays V1.0
Code A2 B1_1 B1_2 B2+ Total
CHN 20 20 20 20 80
JPN 20 20 20 20 80
IDN 20 20 20 60
KOR 20 20 20 20 80
THA 20 20 20 60
TWN 20 20 20 20 80
HKG 20 20 40
PAK 20 20
PHL 20 20 40
SIN 20 20 40
Total 120 120 200 140 580
Number of merged files: [6 (A2)+6 (B1_1)+10 (B1_2) +7 (B2+) = 29] X 2 topics X 2 (ORIG/EDIT) = 116
The ICNALE Edited Essays V0.3 (2017 June)
The data of learners in KOR and IDN were added.
The structure of the Infosheet has been changed.
The module name has been changed.
The ICNALE-Proofread V0.21 (2017 April)
The error in the file name was corrected.
(Wrong) W_JPN_PTJ0_003_B2_0_EDIT.txt -> (Correct)W_JPN_PTJ0_004_B2_0_EDIT.txt
The ICNALE-Proofread V 0.2 (2017 April)
The data of learners in THA and TWN were added.
The ICNALE-Proofread V 0.1 (2016 August)
The data of learners in CHN and JPN were released.
5. ICNALE Global Rating Archives
About
The ICNALE Global Rating Archives (GRA) is a collection of rubric-based ratings of 140 speeches (initial 90 seconds of the role-play utterances from the interviews of the ICNALE Spoken Dialogues) and the same number of essays (taken from the ICNALE Written Essays) by 80 raters with varied L1 and occupational backgrounds. The ICNALE GRA also includes the fully edited version of the 140 essays, which enables users to compare the raters' subjective judgement on language accuracy and the degree of actual language problems existing in texts. The ICNALE GRA project aims at offering the data for (1) clarification and redefinition of "good speeches/essays," (2) reconsideration of the traditional view that L2 assessment should be done solely by professional native-speaker raters, and (3) adoption of a new yardstick in contrastive interlanguage analysis (CIA).
Participants and Samples
The ICNALE GRA includes the rating of 280 samples (140 speeches + 140 essays) by 80 raters. The total number of the assessments is 22,400.
History
The ICNALE GRA project began in April, 2020 April. The data collection will be completed by March 2023.
Updates
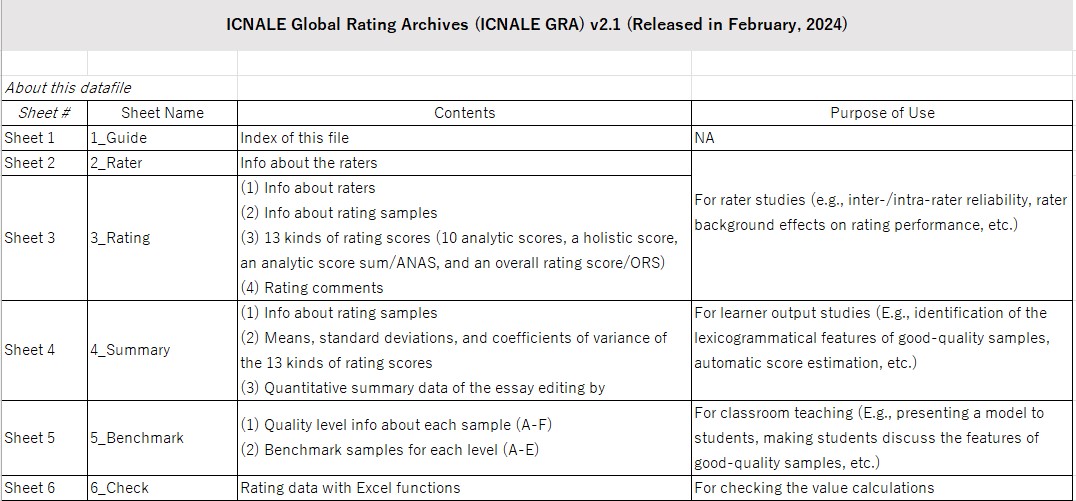
The ICNALE GRA V 2.1 (2024 March)
The rating sheet was totally modified for clearer presentation of the collected data. It now consists of six sheets. How to use the rating sheet is explained in Ishikawa (2024) "The ICNALE Global Rating Archives: A New Assessment Dataset for Learner Corpus Studies."
The ICNALE GRA V 2.0 (2023 October)
Speeches and essays were rated by 80 raters, respectively (160 raters in total). The number of assessments is 22,400. V2.0 is the first version released to the public.
Rater Background (V2.0)
Speech Rater (N=80)
Age: 20s(20), 30s(36), 40s(17), 50s(3), 60s(3), 70s+(1)
Sex; Female (40), Male (40)
L1: Arabic (1), Cantonese (1), Chinese(9), English (6) Filipino (13), French (1), German (1), Hindi (1), Hmong (1), Indonesian (6), Japanese (9), Korean (3), Lao(10), Malay (2), Portuguese (1), Punjabi (1), Punjabi/Urdu(1), Sinhala (1), Thai(6), Urdu(2), Uyghur(1), Vietnamese (1), Yoruba(1)
Educational background: BA(29), HS(1), MA(35), Ph.D. (15)
Proficiency levels (self-report) (Near)NS (12), B1(2), B2(19), C1(33) , C2(14)
Job type: Business (15), English education (42), Education (not English) (13), Grad students (10)
Types of English teachers: HS English teacher (3), Language School English teacher (8), Univ. English teacher (27), English language tester (2)
Essay Rater (N=80)
Age; 20s (16), 30s(40), 40s(15), 50s(5), 60s(3), 70s+(1)
Sex: Female (49), Male (31)
L1: Arabic (1), Bangla (1), Chinese (5), English (9), Filipino (11), French (1), German (1), Hmong (1), Indonesian (5), Japanese (12), Konkani (1), Korean (3), Lao(12), Malay (3), Punjabi/Urdu (1), Sinhala (1), Spanish (1), Thai(6), Urdu(3), Vietnamese (1)
Educational background; High school (2), BA(25), MA(38), Ph.D. (15)
Proficiency levels (self-report): (Near)NS (15), B1 (4), B2(17), C1(32), C2(12)
Job type: Business (18), English education (47), Education (not English) (12), Grad Students (4)
Types of English teachers: HS English Teacher (3), Language School English teacher (7), Univ. English teacher (3), English Language Testers (2)
The ICNALE GRA V 1.0 (2022 November)
Speeches and essays were rated by 60 raters, respectively (120 raters in total). The number of assessments is 16,800. V1.0 was released only to the project members. This version was used for the analyses in Ishikawa (2023).
Rater Background (V1.0)
Gender [Speech Assessment] female (29), male (31) [Essay Assessment] female (34), male (26)
Proficiency [Speech Assessment] B2 (18), C1 (20), C2 (14), (near-) ENS (8) [Essay Assessment] B2 (15), C1 (24), C2 (12), (near-) ENS (9)
Occupation [Speech Assessment] business (6), English teacher (32), other teacher (7) [Essay Assessment] business (7), English teacher (35), other teacher (8)
Rating experiences [Speech Assessment] never (7), 1–5 times (17), 6+ times (36) [Essay Assessment] never (7), 1-5 times (13), 6+ times (40)
L1 [Speech Assessment] Chinese (10), English (2), Filipino (15), Indonesian (3), Japanese (9), Korean (3), Lao (6), Thai (5) [Essay Assessment] Chinese (5), English (4), Filipino (14), Indonesian (3), Japanese (11), Korean (3), Lao (6), Thai (6)
The ICNALE GRA V 0.1 (2021 August)
Speeches and essays were rated by 40 rater, respectively (80 raters in total). The number of assessments is 11,200. V 0.1 was released only to the project members.