ICNALE: The International Corpus Network of Asian Learners of English
A collection of controlled essays and speeches produced by learners of English in 10 countries and areas in Asia
Project Leader: Dr. Shin'ichiro Ishikawa, Kobe University, Japan (iskwshin@gmail.com)
Last updated 2026/1/20
Why should I use the download version?
Although the ICNALE Online is an easy and powerful query tool, we would like to advise you to use the ICNALE download version for your research. Using the download version has many merits.
1) You can access learner attribute data, which is available only in the download version.
2) You can make varied sub-copora for your research. For example, if you are interested in the gender difference in learner essays, you can compare the essays written by male students and those by female students. (See how to do it)
3) You can access the updated data. Please note that we currently do not update the data on the ICNALE Online.
4) You can scrutinize the data with your favorite concordancers and/or corpus analytical tools.
5) Using the data stored in your PC guarantees replicability of your research.
How can I download the data?
The ICNALE Development Team offers a full access to the data collected in the project as well as several tools developed by the project team. Please download the file(s) you need from the links below. Registered users are given a password for unzipping the file(s).
First, obtain the "ICNALE Participant Background Survey Sheet (Version 2026/1), " which includes detailed background data about the participants.
| Core Modules | ||||
|---|---|---|---|---|
| Modules | Updated | N. of samples | N. of tokens | Contents |
| Spoken Monologues (SM) v2.1 > Data (Incl. audio link) |
2023/6 | 4,400 | c 500,000 | 60-second monologues about two common topics. |
| Spoken Dialogues (SD) v1.4 > Data (incl. video link) |
2023/6 | 4,250 | c 1,600,000 | 30-40-minute oral interviews including picture descriptions and role plays, and 3-5-minute L1 follow-up interviews |
| Written Essays (WE) v2.6 > Data |
2025/1 | 5,600 | c 1,300.000 | 200-300-word essays about two common topics |
| Written Essays Plus (WEP) v0.6 > Data |
2026/1 | 2,340 | c 570,000 | 200-300-word essays about two common topics written by college students in Bangladesh, Brunei, Cambodia, India, Laos, Malaysia, Myanmar, Nepal, and Vietnam. |
| Edited Essays (EE) v3.1 > Data |
2023/6 | 656 | c 150,000 | Fully edited versions of learner essays about two common topics. Rubric-based essay evaluation data is also included. |
| Additional Modules | ||||
| Written Essays UAE (WE_UAE) v1.0 > Data |
2018/04 | 200 | c 47,000 | 200-300-word essays about two common topics written by college students in the United Arab Emirates. |
| Global Rating Archives (GRA) v2.1 > Data |
2024/3 | 22,400 assessments | --- | Rubric-based ratings of 140 speeches (initial 90 seconds of the role-play utterances in the interviews of the ICNALE Spoken Dialogues) and the same number of essays (taken from the ICNALE Written Essays) by 80 raters with varied L1 and occupational backgrounds. Plus edited version of 140 essays. |
| Software | ||||
| Speech Morphing System 1.0 > Program (10MB) |
2014/10 | --- | --- | Computer software developed for morphing the audio data, which was used in the ICNALE Spoken Monologue project. |
| Annotation Data (Developed by the third party) | ||||
| ICNALE Written Essays with Phrase Structure Annotation 1.0 > Data (2MB) |
2016/06 | 134 | c 33,000 | ICNALE essays manually annotated with phrase structures. This is a product by Dr. Ryo Nagata, Konan University. |
How can I obtain the password?
Register from the The ICNALE User Registration Form. After filling out the form, you can obtain the passwords soon.
Fig. 1 The ICNALE User Registration Form
For researchers in mainland China
You may not be able to access the registration site from China. Please send your information (name, institute, position, and the purpose of the use of the data) directly to Dr. Shin Ishikawa (iskwshin@gmail.com)
Frequently Asked Questions
1. I already registered, but have not received passwords. What should I do?
---> Please contact the ICNALE team.
2. I am using a Mac PC and cannot open the file. Any helps?
---> Please read this.
3. I am in China and cannot access the registration form on the Google Server. Any helps?
---> Send your name, your institute, your position (eg. Prof./ Grad Student/ Undergrad/ Independent researcher etc.), and the purpose of using the ICNALE directly to the ICNALE team.
4. How should I cite the ICNALE in my research papers?
---> Please read this.
5. How can I analyze the download version?
---> You need a corpus analytical software. Please try Antconc and/or Wordsmith (Free Version).
6. Encoding seems to be incompatible with my software. Any helps?
---> All the ICNALE texts are encoded in the UTF-8 containing the BOM character (Info). When using a concordance software, you may need to set the character code before conducting analyses.
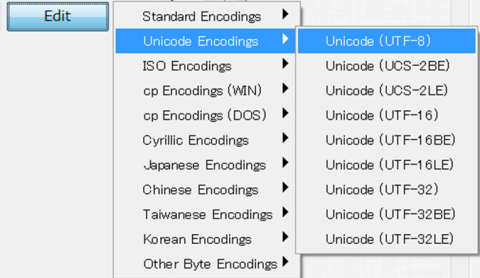
Fig. How to set the character code on the Antconc v3.5.2 (Global Setting --> Character Encoding)
7. I am using the Wordsmith. It always tries to convert ICNALE UTF8 files to some other format. How can I stop this?
---> Please remove the check of "Convert from UTF8."
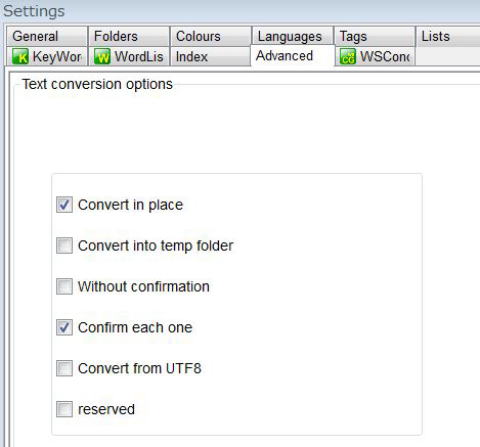
Fig. How to stop the text format conversion on the Wordsmith (Settings --> Advanced)
Folder Structure
Each module includes unmerged and merged text sets. The latter includes POS-tagged texts.
Unmerged --- Individual (Only for the ICNALE Edited Essays) / Classified
Merged --- Plain Text / Tagged
File Naming Rules
Fully updated in June 2023, and partly modified in October 2023.
General Rules
1. Spoken Monologues (SM)
Module _Region _Task _Student ID _CEFR
SM _CHN _PTJ1 _001 _B1_2
2. Spoken Dialogues (SD)
Module _Region _Task (Code, Topic, Task, main/QA) _Student ID _CEFR
SD _CHN _04 _PTJ _PIC _QA _001 _B1_2
3. Written Essays (WE)/ Written Essays Plus (WEP)
Module _Region _Task _Student ID _CEFR
WE _CHN _PTJ0 _001 _B1_1
4. Edited Essays (EE)
Module _Region _Task _Student ID _CEFR _Editing
EE _CHN _PTJ0 _001 _B1_1 _ORIG
EE _CHN _PTJ0 _001 _B1_1 _EDIT
5. Global Rating Archives (GRA) ---Edited Essays---
Module _Task _Sample ID _Editing
GRA _PTJ0 _001 _ORIG
GRA _PTJ0 _001 _EDIT
Module
SM: Spoken Monologues
SD: Spoken Dialogues
WE: Written Essays
WEP: Written Essays Plus
EE: Edited Essays
GRA: Global Rating Archives
Region
CHN, ENS, HKG, IDN, JPN, KOR, PAK, PHL, SIN, THA, TWN (SD only) MYS
(WEP only) BGD, BRN, KHM, IND, LAO, MYS, MMR, NPL, VNM
Task
PTJ0: part-time job essay
PTJ1/2: 1st / 2nd Part-time job speech
SMK0: non-smoking essay
SMK1/2: 1st / 2nd no-smoking speech
SD Task
01_XXX_INT_xx (Introduction)
03_PTJ_PIC_xx (Picture Description)
04_PTJ_PIC_QA
06_PTJ_ROL_xx (Roleplay)
07_PTJ_ROL_QA
09_SMK_PIC_xx
10_SMK_PIC_QA
12_SMK_ROL_xx
13_SMK_ROK_QA
14_XXX_REF_xx (Final Refelction)
Student ID
001-999: Participant identification codes (For NNS)
CEFR
(For Learners)
A2_0: CEFR A2
B1_1: B1 lower
B1_2: B1 upper
B2_0: B2+
(For NS)
XX_0 Unclassified
XX_1: Students
XX_2: Teachers
XX_3: Others
How to Read a Participant Information Sheet
The number of words
PTJ1 (wds)
Number of words in part-time job essays OR monologue (1st trial)
PTJ2 (wds)
Number of words in part-time monologue (2nd trial)
SMK1 (wds)
Number of words in non-smoking essays OR monologue (1st trial)
SMK2 (wds)
Number of words in non-smoking monologue (2nd trial)
Personal Attributes
Country
Countries and regions
Sex
Male or Female
Age
y/o
Grade/ Degree
1-4, or MA for learners/ BA, MA, Ph.D. for ENS
Months of Stay (< n months)
Months of stay in English-speaking countries
Yrs of Working (NS)
Years of working (only for ENS)
ENS Type
1 (College students), 2 (Teachers), 3 (Other adults)
Major/ Occupation
Faculty or Department for Learners/ Jobs (for ENS only)
Academic Genre
Humanities, Social Sciences, Science & Technology, Life Sciences
Proficiency
Test
Type of the English proficiency test that a participant has taken (e.g.: TOEIC, TOEFL, IELTS)
Score
Scores in the test mentioned above
TOEIC-Converted
Test scores converted to the TOEIC. Scores in the TOEFL PBT test were converted into the TOEIC score, using the regression formula: TOEIC = TOEFL*4.167 - 1497
TOEIC-S
Scores in the TOEIC Speaking Test
TOEIC-W
Scores in the TOEIC Writing Test
VST
Scores in the 5k-words voc size test (/50) (Nation & Beglar, 2007)
CEFR
CEFR level (A2, B11, B12, B2+) estimated from the scores in the proficiency test or Voc Size Test
Self Ev
Self evaluation scores (only for Spoken Monologue)
Attitudes
INTM
Integrative motivation score (See http://language.sakura.ne.jp/icnale/about.html)
INSM
Instrumental motivation score
INTM+INSM
Strength of motivation in general
INTM-INSM
The difference between two kinds of motivations
Like to talk in L2
Willingness to communicate in L2
Like to talk in L1
Willingness to communicate in L1
L2 Learning Background
Primary/ Secondary/ College
How much have learners used English at each of the school levels? (See http://language.sakura.ne.jp/icnale/about.html )
Inschool/ Outschool
How much have learners used English in classes or out of the classes? (See http://language.sakura.ne.jp/icnale/about.html)
Listening/ Reading/ Speaking/ Writing
How much have learners studied each of the four basic English skills? (See http://language.sakura.ne.jp/icnale/about.html)
NS
How often have learners been taught by English native speakers?
Pronunciation
How often have learners been taught English pronunciation?
Presentation
How often have learners been taught speeches and presentations?
Essay W
How often have learners been taught essay writing?
Additional info in the Written Essays Module
Editor
HAC, JES, LC, MH, NH (Editors’ codes)
A (Added) / D (Deleted)
Number of words added/ deleted in editing
A+D
Total number of words changed (namely added or deleted) in editing (a.k.a “edit distance”)
Content (/12), Organization (/12), Vocabulary (/12), Language Use (/12), Mechanics (/12)
Scores given by the editors. Rating rubrics are based on the ESL Composition Profile (Jacobs et al., 1981). Also see Ishikawa (2018).
Total 1 (%)
Simple Mean: T1= (Con+Org+Voc+LanU+Mec)/60*100
Total 2 (Weighted %)
Weighted Mean (Based on the weights proposed in Jacobs, et. al., 1981): T2= (Con/12*30 + Org/12*20 + Voc/12*20 + LanU/12*25 + Mec/12*5) (Corrected in April, 2018)
Additional info in the Spoken Dialogue Module
Time (L2/ L1 Intv) (mm:ss/ ss)
Duration of an L2 interview/ Duration of a follow-up L1 interview
Time (All) (mm:ss)
Duration of the total interview
L2 Tokens
The number of tokens in an L2 interview (student's turn only)
L2 Types
The number of types in an L2 interview (student's turn only)
L2 STTR (/100)
Standardized type/token ratio
L2 MWL
Mean word length (in the number of letters)
L2 MSL
Mean sentence length (in the number of words)
L2 Fluency (Tokens/ M)
L2 Speed Fluency Index
L1 Tokens (Letters)
The number of tokens in a follow-up L1 interview (student's turn only)
L1 Fluency (Letters/ M)
L1 Speed Fluency Index
File Size (MP4 All Intv: MB)/ File Size (MP3 L2 Intv: MB)
Sizes of the accompanying video and audio files