

コーパスに基づく語彙表開発
■コーパス研究と語彙研究
言語を構成する要素は,音素,音素結合,語,語結合,句,節,文,段落,テキスト,談話など,さまざまなレベルがありますが,コーパス系の言語研究は中でも語およびその総体としての語彙を対象とすることが多くなっています。語彙はほかの言語構成要素と比較すると,構造が シンプルで計量的研究と親和性が高いためと考えられます。
コーパス準拠型語彙研究には,特定の基準を満たす語彙の抽出を目指す語彙選定,特定語の振る舞いを調べる語法研究,語彙を手掛かりとしてテキストを調べるテキスト研究などが想定されますが,中でも最も基本になるのは語彙選定研究でしょう。
石川研究室は,古くから,コーパスを用いた語彙の計量的分析と,語彙選定の手法開発の研究を行っています。ここでは,研究室でこれまでに開発した語彙表,および,研究室が協力して開発した語彙表をいくつか紹介します。いずれも,最終プロダクトとしての語彙表そのものよりも,主観や直観といった計量しにくいパラメタを何らかのかたちで計量化して合理的な形でコーパス頻度と接合させる手法開発が研究の主な狙いとなっています。
英語上級学術語彙表BABILON 2000(2018年)
英語学術語彙表としては,Coxhead(2000)のAcademic Word List(AWL)が有名です。AWLはすぐれた語彙表ですが,(1)元となるコーパスが非公開で検証できない,(2)コーパスに年代や地域の偏りが含まれている可能性がある,(3)語彙選定には頻度とレンジを考慮しているものの,最終的な重要度の決定は頻度のみで行っている,(4)英語学習者の多くは接辞について十分な知識を持っておらず,派生形を独立語として扱わないのは不適切である,(5)頭字語や略号を一律に削除するのは問題がある,(6)学術英語で散見される語の中にAWLでカバーされていないものも少なくない,といった課題もあります。そこで本研究においては,AWLの課題をふまえつつ,(1’)検証可能な公開コーパスのデータを用い(OpeN),(2’)年代と地域的なバランスを考慮しつつ(Balanced),(3’)頻度とレンジを合成した学術語彙重要度指標を基準として(Integrated),(4’)派生形を除外したレマの単位で(Lemma-based),(5’)頭字語や略号も包含する幅広い語の定義を採用した上で(Broad),(6’)GSL+AWLを超えるレベルを対象に(Advanced),学術語彙の選定を行うこととし,新たに2,000語を抽出しました。Babilonとは,上記の6つの理念のアナグラムになっています。
ダウンロード
関連論文
石川慎一郎(2018)「上級英語学術語彙表 “BABILON 2000”の開発― 6つの理念に基づく新しいEGAP語彙選定の試み―」石川有香(編)『ESP語彙研究の地平』金星堂. pp. 2-20.
日本人学習者のための英語連語リスト English N-gram List for Japanese Learners of English (ENL-J) (2017年)
英語語彙表にはすぐれたものが多くありますが,連語のリストとなると,使用できるものがきわめて限られています。そこで,本研究では,日本人英語学習者を取りまくターゲット(母語話者コーパス),インプット(教科書,試験),アウトプット(作文)の三元データを連関させた「TIO分析」に基づくn-gramリストを開発しました。これは,以前に開発したEnglish Trigram Databaseの拡張版で,2~4語連鎖のデータが収録されています。使用者は,エクセルデータを加工することで,母語話者は多く使うのに教科書では出てこないn-gramや,教科書では出ているのに学習者が使えないn-gramなどを簡単に特定し,既存の教材や学習者のL2運用の課題を検討することができます。
ダウンロード
※2023/6 ターゲットとの乖離度が「頻度に基づく」という解説をつけていましたが、実際には「重要度に基づく」データでした。誤りを修正するとともに、重要度・頻度・レンジの各々についての乖離度を示すように修正・増補しました。
関連論文
石川慎一郎(2019)「英語教育における連語:ターゲット・インプット・アウトプットの三元コーパス分析をふまえたEnglish N-gram List for Japanese Learners of English(ENL-J)の開発と利用」仁科恭徳 /吉村由佳 /吉川祐介(編)『言語分析のフロンティア』金星堂. pp. 32-47.
大学入試センター試験(1987~2014年度)英語語彙表 CT_Voc(2017年)

大学入試センター試験の英語問題(過去27年分,合計約19万語)のテキストデータから語彙を切り出しました。レマ化処理を行い,粗頻度2以上の語をリスト化したところ,全体で4,015語が得られました。Tree Taggerを用い,品詞(POS)情報を付与しています。大学入試センター試験は,周知のように,高校の学習範囲を逸脱しない形で作問がなされています。つまり,大学入試センター試験の出題語彙を見ることは,日本の高校生の語彙力水準を推定する上で有効な手段になると言えるでしょう。とくに,大学での語彙指導を考えようとする場合,従来,どこからスタートすべきか,言い換えれば,どこまでを既習語彙とみなしうるかの線引きが非常に難しかったわけですが,本リストを活用することで,そうした判断に一定の目安が得られるのではないかと考えます。
ダウンロード
日本人大学生用基本語彙 新JACET8000(2016年)

大学英語教育学会(JACET)が刊行する学会公式語彙表の新版です。旧JACET8000は,イギリス英語を集めたBNCのみに依拠しており,かつ,BNCのデータを総体的に扱っていましたが,新JACET8000は,BNCに加えてアメリカ英語を集めたCOCAを利用し,かつ,小説・新聞・雑誌・学術・話し言葉の5ジャンル別に頻度を出して平均化する手法を採用することで,ベースの頻度ランクの信用性を大幅に向上させています。また,国内の教科書や入試問題などを資料として上位語の順位を補正することで,日本の英語教育の実態への配慮もなされています。石川は,大学英語教育学会基本語改訂特別委員会(委員長:望月正道氏)の副委員長として,頻度処理の基本デザイン等を担当しました。 これは当研究室の単独開発物ではなく,大学英語教育学会の著作物です。
桐原書店「新JACET8000」
ダウンロード
日本人中高生用基本語彙 JEV/HEV(2014年)

指導要領では中学1200語,高校1800語,合計3000語の習得が示されています。日本の中高生の学習実態をふまえると,このうち,中学1200語については,事実上,検定教科書の語彙がその中身を決定していると言えるでしょう。一方,高校の場合は,教科書の種類も多く,レベルも多様であり,結局のところ,高校1800語の内容はあいまいなままです。そのため,高校生は単語集などを頼りとして手探りで語彙学習を行っていますが,何をどこまで覚えるべきかは明確ではありません。
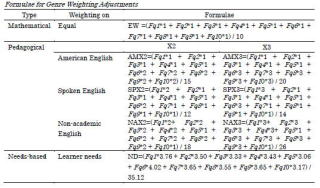
そこで本プロジェクトでは,まず,現行の6種の中学校検定教科書のうち2冊以上で出現している語彙を基準として,中学1200語の実態を示すJEV 1200(Junior High School Level English Vocabulary)を策定しました。その後,1200語に続いて高校生が学ぶべき語彙として,英米2大コーパスの10ジャンル頻度を根拠とするHEV1800(High School Level English Vocabulary)の開発を行いました。HEV1800では,BNCとCOCAから得られた10種のジャンル別頻度データ(イギリス英語の話し言葉,新聞,雑誌,小説,学術文;アメリカ英語の話し言葉,新聞,雑誌,小説,学術文)に対して,1)均等荷重(ME),2)指導要領と日本の英語教育の現状をふまえた荷重(a: 米語荷重,b:話し言葉荷重,c:非学術文荷重。それぞれ100%と200%の荷重),3)学習者の学習ニーズをふまえた荷重(180人の大学新入生に対する学習意向調査アンケート結果に基づく)の合計9種の荷重処理による並べ替えを試行し,すべての調整で共通して上位2100語以内に抽出される語彙を選定するという新しい処理手法を開発しました。HEVは,現代英語の諸相を反映する10ジャンル,また,日本人高校生の多様な英語学習状況を反映した9種の調整において,変わらず上位にくる語がある種の核語彙であり,優先的に習得すべき語であるという理念に基づいています。

JEVとHEVは特定の目的に特化して作ったものではありませんが,各種コーパス(Frown, FLOB,ICE),学術発話(MICASE),ニュース・新聞(CNN, Japan News),映画,センター試験,二次試験など,あらゆるテキストに対して平均85%超過のカバー率を達成しています。先行研究で開発された主要リストと比べて遜色のないカバー率と言えます。HEVは,石川が主幹として開発中の高校英語検定教科書の語彙統制などに使用されています。
関連論文
Ishikawa Shin'ichiro (2015)A New Corpus-Based Methodology for Pedagogical Vocabulary Selection: Compilation of “HEV1800” for Japanese High School Students 『中部地区英語教育学会紀要』44, 41-48
ダウンロード
日本人過剰・過小使用語彙OUUVOC(2013年)
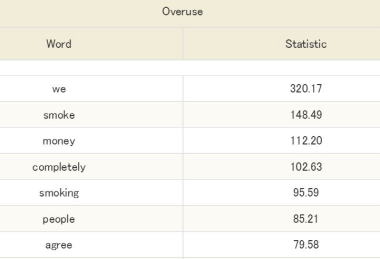

筆者の研究室で開発された世界最大級の英語学習者コーパスICNALEのデータに基づき,日本人学習者が母語話者に比べ,統計的に過剰・過小使用する語彙のリストです。学習者と母語話者に統制環境(同一トピック,同一時間)で作文を行わせることにより,信頼性の高い語彙表となっています。たとえば,日本人学習者は"I think"や"So,..."を多用することなど,従来は教師の直観で論じられていた傾向を客観的に取り出すことが可能になりました。ICNALEにはアジア圏の10か国地域の学習者データが包含されており,それに対応してOUUVOCも各国学習者版が開発されています。日本人用のOUUVOCのデータは,筆者が開発に関与した『ウィズダム和英辞典2版』(三省堂)の執筆に使用されています(上記は石川が執筆した同辞書のthinkのコラムです)。
関連論文
Ishikawa Shin'ichiro (2013) How to Incorporate Findings from Learner Corpus Studies in EFL Dictionaries ―From Misuse to Over/Underuse― In Deny A. Kwary, Nur Wulan, & Lilla Musyahda (Eds.) Lexicography and Dictionries in the Information Age: Selected Papers from the 8th ASIALEX International Conference, 138-144.
ダウン ロード
KUBEE (Kobe University Basic English Vocabulary for Elementary School Students)(2007年)
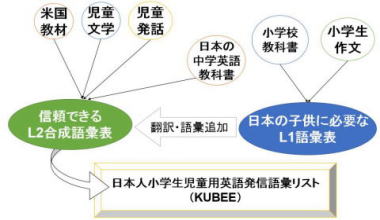

日本の小学校英語のための基本語彙表です。大学附属小学校での英語教育に関わる中で,小学校英語における語彙の扱いがじゅうぶん体系化されていないことを痛感し,信頼できる基本語彙表を提供するという目的で開発を行いました。 一般にコーパス準拠語彙表の開発にあたっては,1)母語話者のみ,2)成人のみ,3)受信のみ,4)目標言語のみとなりがちですが,「日本の小学生のための英語語彙」を考える場合は,1')日本人学習者,2’)児童,3’)発信,4’)学習者母語の4つの点に配慮する必要があります。そこで,この研究では,英米圏の児童・生徒が目にする英語インプットとして児童文学や学校教材を収集し,彼らのアウトプットとして会話産出をデータ化しました。あわせて,日本人児童にとっての母語インプットとして日本の教科書を,また,母語アウトプットとして作文をデータ化しました。これにより,英米児童・日本人児童のインプット,アウトプットの両面を踏まえたユニークな語彙選定がなされました。本リストは,神戸大の附属学校の英語活動の内容チェック資料として使用されるだけでなく,日本放送協会(NHK)の小学生用英語学習番組「えいごルーキーGabby」のスキット開発の基礎データとして使用さ れました。
KUBEE収録語彙の例
taw(おはじき),tupa(さなぎ),lizard(とかげ),bud(芽),goldfish(金魚)
関連論文
石川慎一郎(2007)L1/L2コーパスの解析に基づく児童英語教育のための語彙マテリアル抽出システム の開発―小学校英語教育のための語彙選定の視点―『中部地区英語教育学会紀要』36,317-324
ダウンロー ド
えいごルーキーGabby番組サイト
えいごルーキーGabby DVD
司法ESP語彙 JUDI(English Judicial Vocabulary)(2005年)
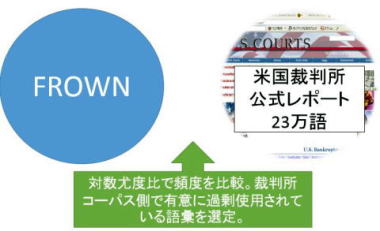
大学の専門課程の英語教育のためのESP語彙表の開発手法を探る中で構築した語彙表です。ターゲットコーパスとして米国司法省の公式文書23万語をコーパス化し,一般的な現代米語コーパス (Frown)と比較し,ターゲットコーパス側で頻出している語彙を抽出しました。ただ,この研究を通して,ESPドメインが必ずしも自足的なものではなく,レファレンスコーパスとの比較だけで真に当該ジャンルの固有語彙を抽出するには問題が残ることも示されまし た。たとえば,一般コーパスと比較して司法文書の特徴語彙を取り出すと,そのなかには経済用語が多く含まれます。裁判事例として経済事件が多いことによりますが,この場合,司法コーパスに含まれる経済語彙を「司法ESP語彙」と呼ぶのか「経済ESP語彙」と呼ぶのかは難しい判断になります。今後のESP語彙表開発では,任意のESPジャンル内に含まれる他分野のESP語彙の自動識別手法の開発が必要になってくるでしょう。
JUDI-vocの語彙の一部
judicial,judiciary,judge,administrative,bankruptcy,debtor,conference,district,civil,penalty
関連論文
石川慎一郎(2005)司法英語ESP語彙表開発の試み:FROWNコーパスと米国司法文献 コーパスの比較に基づく特徴語の抽出『神戸大学国際コミュニケーションセンター論集』1, 13-28
ダ ウンロード
日本人大学生用英語基本語彙 旧JACET8000(2003年)

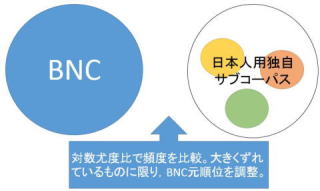
大学英語教育学会(JACET)が刊行する公式の語彙表です。日本人大学生のために重要な英語語彙8000語をBNCを一次資料とし て選定しました。この語彙表が重要なのは,母語話者の産出を集めたコーパスから得た頻度に全面的に依拠するのではなく,日本の英語教科書や児童文学,グレーディッドリーダーなど,教育的価値が高いと思われるデータを独自に集めてコーパス化し,BNC頻度順位と独自コーパス頻度順位を比較し,大きくずれのあるものについて順位補正を行うという処理法を開発したことです。これは当研究室の単独開発物ではなく,大学英語教育学会基本語改訂委員会の著作物です。JACET8000 は,学会の出した語彙表という性質もあり,多くの研究や,辞書を含む教材,また,教育現場で活用されて現在に至っています。なお,改訂計画が現在進行中です。(追記:2016年に新JACET8000が公刊されました。)
関連論文
Uemura Toshihikok & Ishikawa Shin'ichiro (2004) JACET 8000 and Asian TEFL Vocabulary Initiative The Journal of Asia TEFL (The Asian Association of TEFL),1(1)333-347
桐原書店「JACET8000英単語」
JACET8000 分析ツール
ダウンロード